import streamlit as st from streamlit_extras.add_vertical_space import add_vertical_space from PyPDF2 import PdfReader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_huggingface import HuggingFaceEmbeddings from langchain.vectorstores import FAISS from langchain_deepseek import ChatDeepSeek from langchain.chains.question_answering import load_qa_chain import pickle import os from dotenv import load_dotenv load_dotenv()
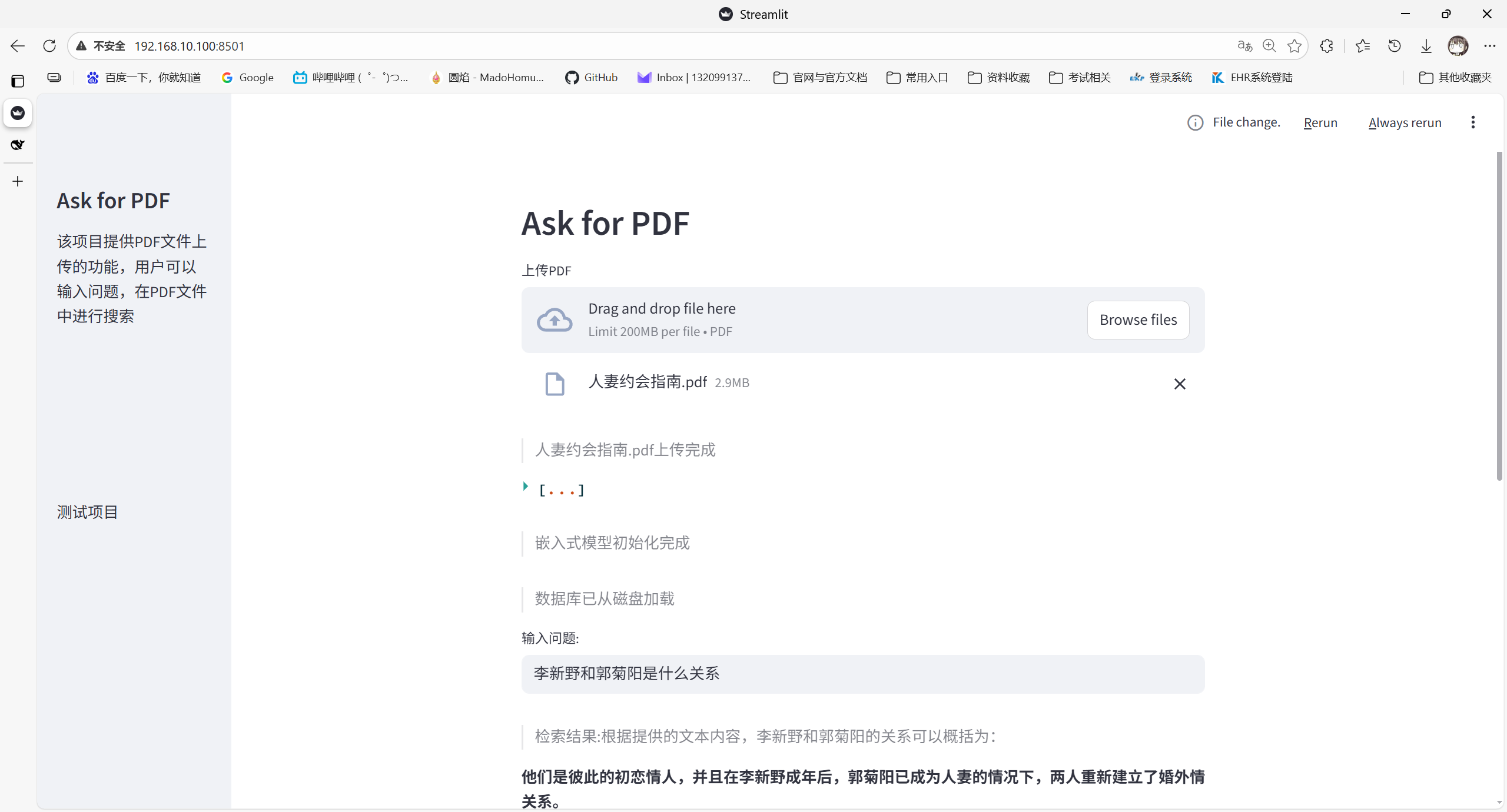
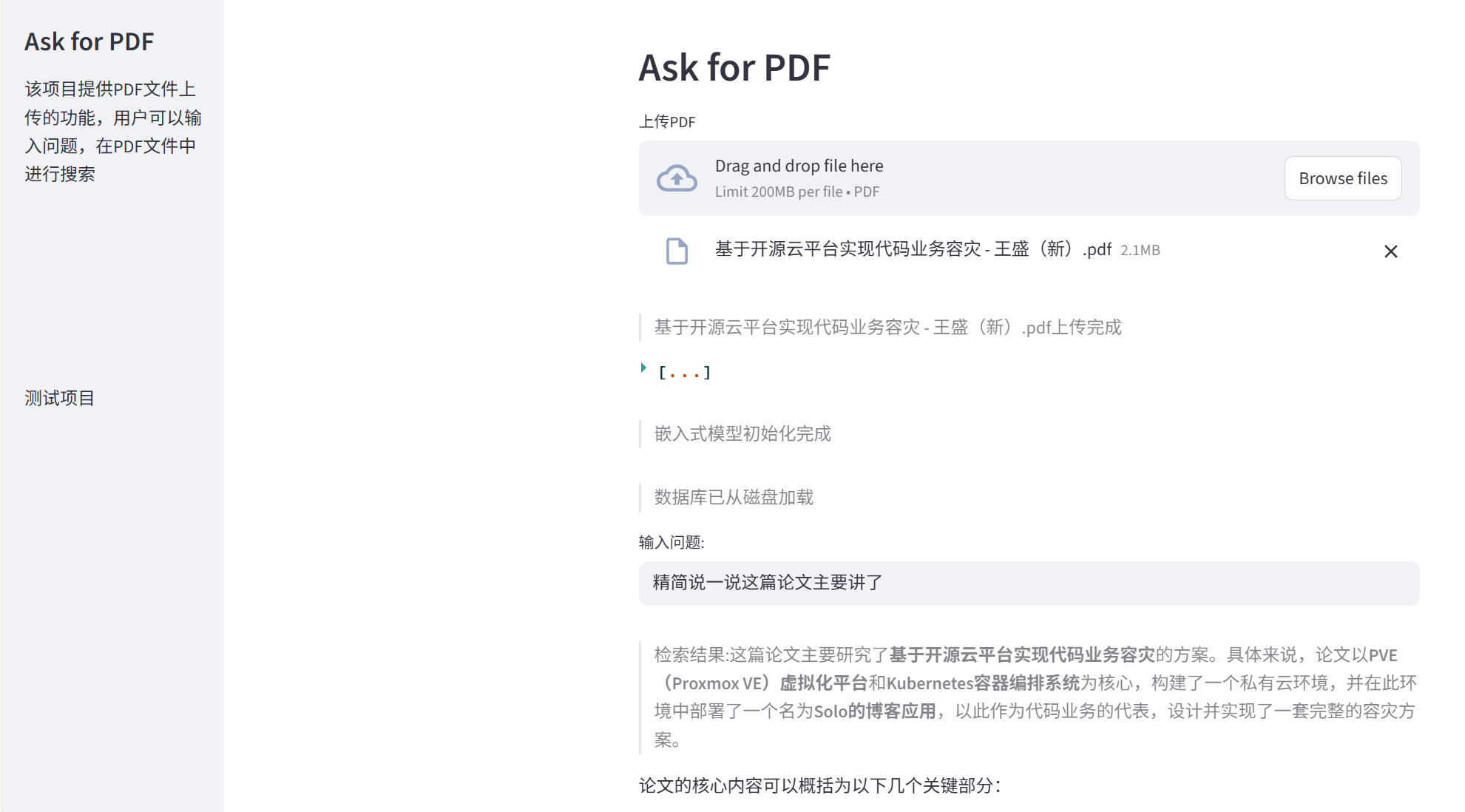
# 1.创建UI with st.sidebar: st.title("Ask for PDF") st.markdown("该项目提供PDF文件上传的功能,用户可以输入问题,在PDF文件中进行搜索") add_vertical_space(10) # 空五行 st.write("测试项目")
# 写一个main作为程序入口 defmain(): st.header("Ask for PDF") # 文件上传器 pdf = st.file_uploader("上传PDF", type="pdf") if pdf isnotNone: st.write(f">{pdf.name}上传完成") # 2.读取pdf pdf_reader = PdfReader(pdf) text = "" for page in pdf_reader.pages: text += page.extract_text() # st.write(text) # 3.文本切割 text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20, length_function=len) texts = text_splitter.split_text(text) st.write(texts) # 4.向量初始化 embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-mpnet-base-v2", model_kwargs={'device': 'cpu'} ) st.write(">嵌入式模型初始化完成") store_name = pdf.name[:-4] # 如果数据库文件已存在,直接使用 if os.path.exists(f"{store_name}.pkl"): withopen(f"{store_name}.pkl", "rb") as f: vectorstore = pickle.load(f) st.write(">数据库已从磁盘加载") else: vectorstore = FAISS.from_texts(texts, embeddings) # 数据库保存 withopen(f"{store_name}.pkl","wb") as f: pickle.dump(vectorstore, f) st.write(f">数据库已保存为 {store_name}.pkl") # 5.用户输入问题,检索数据库 query = st.text_input("输入问题:") if query: docs = vectorstore.similarity_search(query,k=30) llm = ChatDeepSeek(model="deepseek-chat", temperature=0.7) chain = load_qa_chain(llm, chain_type="stuff",) reponse = chain.invoke({"question": query,"input_documents": docs}) st.write(f">检索结果:{reponse['output_text']}")