
计算资源虚拟化包括三个方面,CPU虚拟化、内存虚拟化、IO虚拟化,其中IO虚拟化包括存储虚拟化与网络虚拟化
- CPU虚拟化
- 内存虚拟化
- 存储虚拟化
- 网络虚拟化
虚拟化同质原则:
- 每个虚拟机的内核需要独立的硬件运行空间,虚拟机的内核认为自己是物理机内核
- 虚拟机的硬件性能应该尽可能和宿主机硬件性能保持一致
虚拟化架构类型分类:
- 寄居虚拟化——hypervisior层建立在操作系统之内,需要通过app对资源进行虚拟,比如VMwareWorkstation
- 裸金属虚拟化——hypervisior层一定程度上与内核层是同一层,比如kvm、xen、exsi
- 操作系统虚拟化(容器虚拟化)——容器不具备完整的kernal,比如docker
CPU虚拟化
时间虚拟化
hypervisor层会对CPU进行时间分片,通过vCPU方式分给VM
分配给VM后,又会为了VM中的进程进行第二次时间分片
指令虚拟化
一共有4种等级的CPU指令
Ring0 : 内核态进程(kernel)可以执行 (特权指令)
Ring1: 默认情况下无人执行
Ring2: 默认情况下无人执行
Ring3: 用户态进程可以执行 (用户指令)
指令根据敏感性,分为:
1.敏感指令:影响计算机全局状态指令,比如关机
2.非敏感指令: 不会影响计算全局状态
当用户态进程(如QQ)需要调用敏感指令(如IO指令)时,需要发起system call请求内核,让内核态进程执行Ring0的指令
RICS精简指令集(如mac)
在RISC架构中,所有RING3/ 用户态指令 都是非敏感指令
所以就有了陷入-模拟的解决方案
陷入-模拟
1.特权降级——hypervisor将VM-kernal可执行的级别降至ring1
2.VM-kernal发送ring0,变成ring1,cpu向hypervisor发起告警
3.hypervisor收到告警后,进行翻译,模拟执行
CICS复杂指令集(x86)
在x86结构中,有一部分ring3非特权指令,是敏感指令。会导致虚拟化平台全局状态受影响。
全虚拟化(fullvirtualized - FV) —— vmware workstion、exsi
当在X86架构中,如果使用全虚拟化,意味系统OS ,用户态/内核态发出指令需要被hypervisor捕捉。Hypervisor模拟 ring1 / ring3(敏感指令)。
即虚拟化层将所有ring1和敏感的ring3指令全部捕捉并进行翻译
缺点: hypervisor需要一直判断指令类型,模拟执行(二进制的翻译),性能损失/开销大
优点: 不需要修改虚拟机OS-kernel,可以模拟安装windows, linux
半虚拟化(ParaVirtualized -PV)——xen
半虚拟化技术打破原则-同质原则,需要修改虚拟机OS-kernel
这种情况下,VM-kernal的ring3敏感指令会直接hyper call到hypervisor层
VM-kernal的ring0会system call给Host-kernal,Host-kernal再hyper call
然后Hypervisor模拟执行
缺点: 打破原则,修改虚拟机OS-kernel(不支持windows)
优点: 效率高,开销小
硬件辅助(全)虚拟化—— KVM、xen、esxi
增加一个CPU指令的层次——特权层次
Ring0-3 非根模式
Ring -1 特权模式-hypervisor层
CPU监控ring0和ring3的指令,如果有将其hyper call给hypervisor层,使用特权模式执行
AMD ——amd-v(主板中开启) svm
intel ——vt-x(主板中开启) vmx
通过lscpu或cat /proc/cpuinfo进行查看是否支持硬件辅助虚拟化
KVM的虚拟化只能使用硬件辅助虚拟化
xen可以使用半虚拟化或者硬件辅助虚拟化
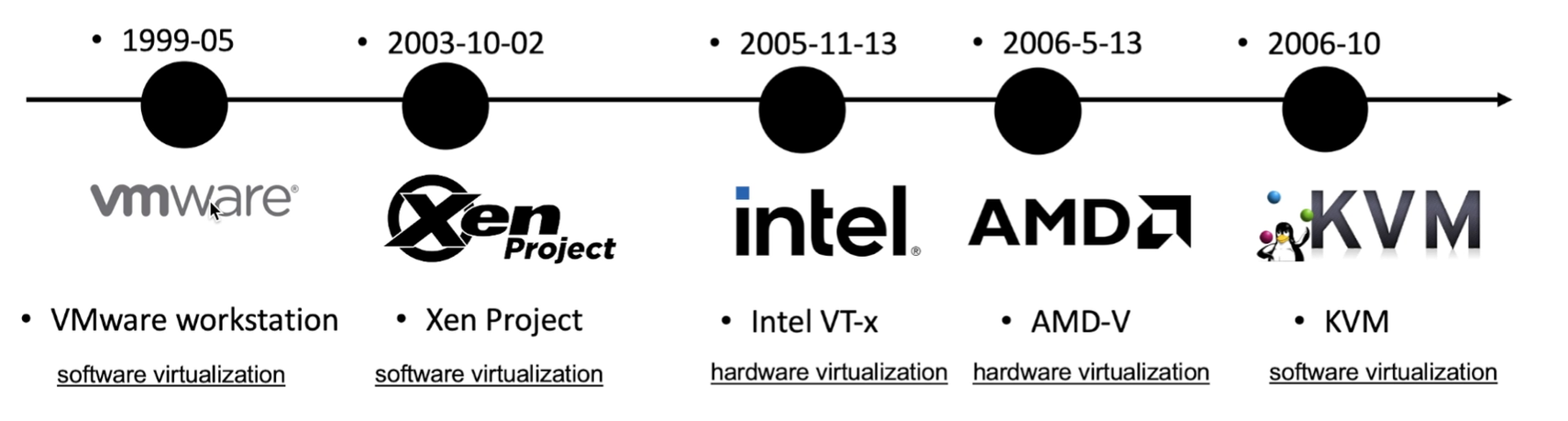
现状:
kvm必须使用硬件辅助虚拟化
VMware以前用全虚,现在用硬件辅助虚拟化
xen可以用半虚或硬件辅助虚拟化;如果没有打开硬件辅助虚拟化,就用半虚
内存虚拟化
有两个概念需要提前了解,我直接复制AI写的来了:
MMU(Memory Management Unit)内存管理单元
TLB(Translation Lookaside Buffer)地址转换后援缓冲器,也被称为“快表”(映射表)
内存虚拟化有两个层面:
1.内核识别到的内存分配给app——进行内存分页,通过映射表分配
2.hypervisor识别的内存分配给VM
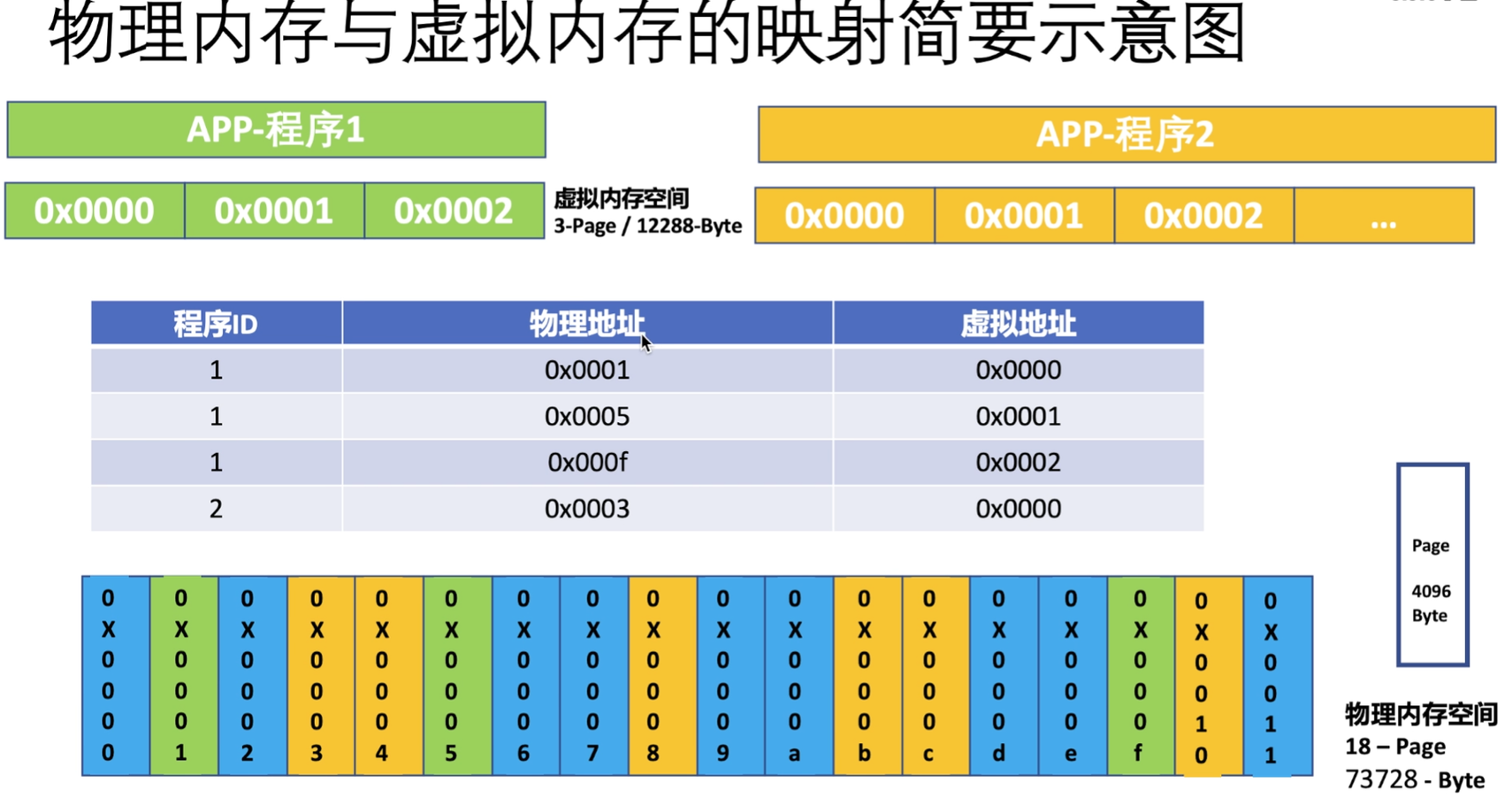
内核态hypervisor(kvm,xen,exsi)
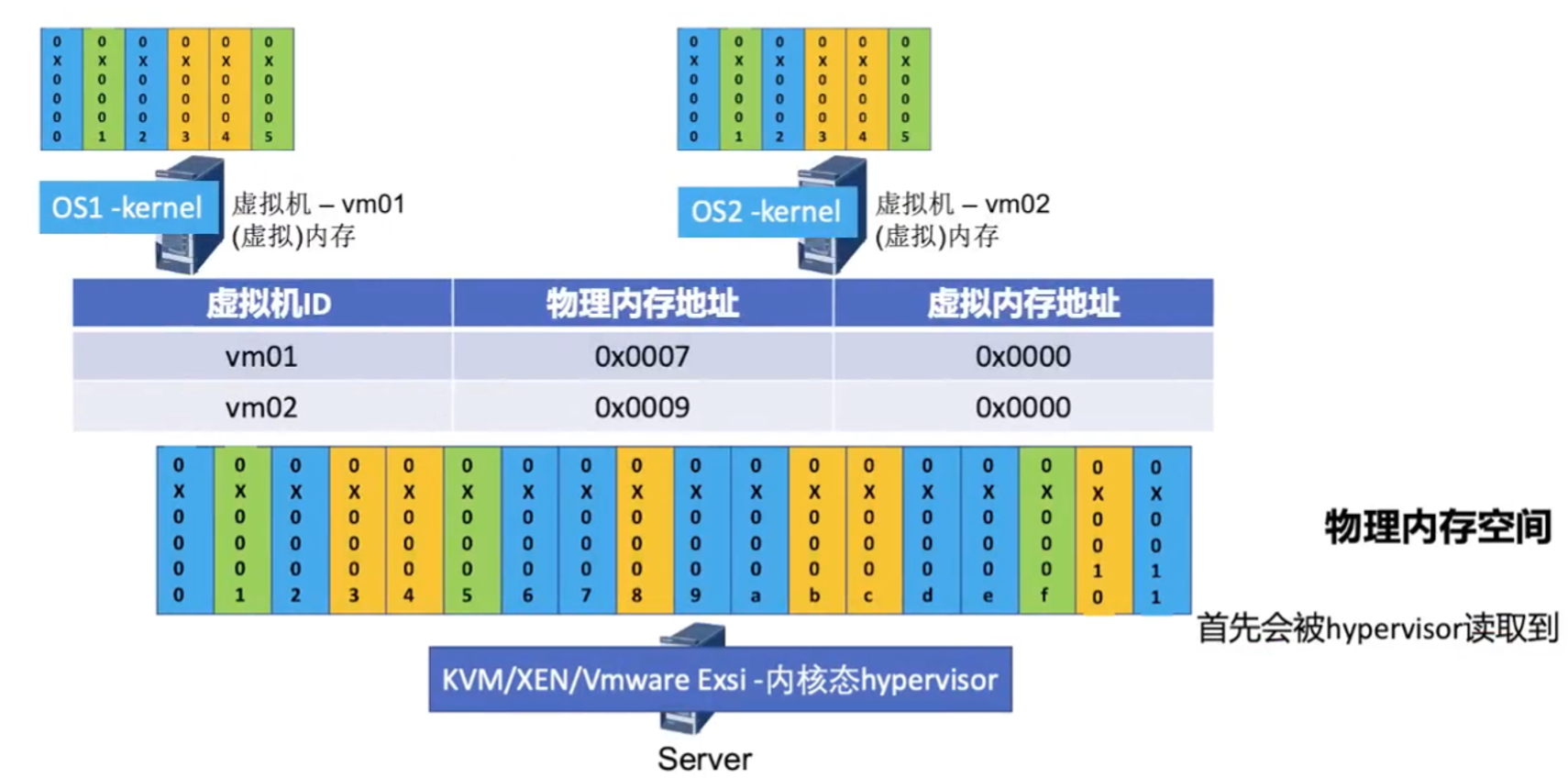
综合上述这两个过程
在内存虚拟化中,需要完成两次内存映射,即一次分给VM,一次分给app
- 物理内存地址空间会首先备hypervisor(物理机内核)读取,该内存地址空间称之为HPA
- 在进行虚拟化的任务,hypervisor会将内存地址进行映射并分配给虚拟机,该地址在hypervisor视角认为该内存为HVA,该地址在虚拟机的内核视角会认为该内存地址为物理内存PA(GPA)
- 虚拟机内核会继续为该内核之上所运行的应用程序继续分配内存地址空间,在虚拟机内核视角中,认为该内存为虚拟内存VA(GVA)
内存软件(全)虚拟化
在上面这个过程中,需要在宿主机和VM都需要使用,要使用两次,就是内存软件虚拟化
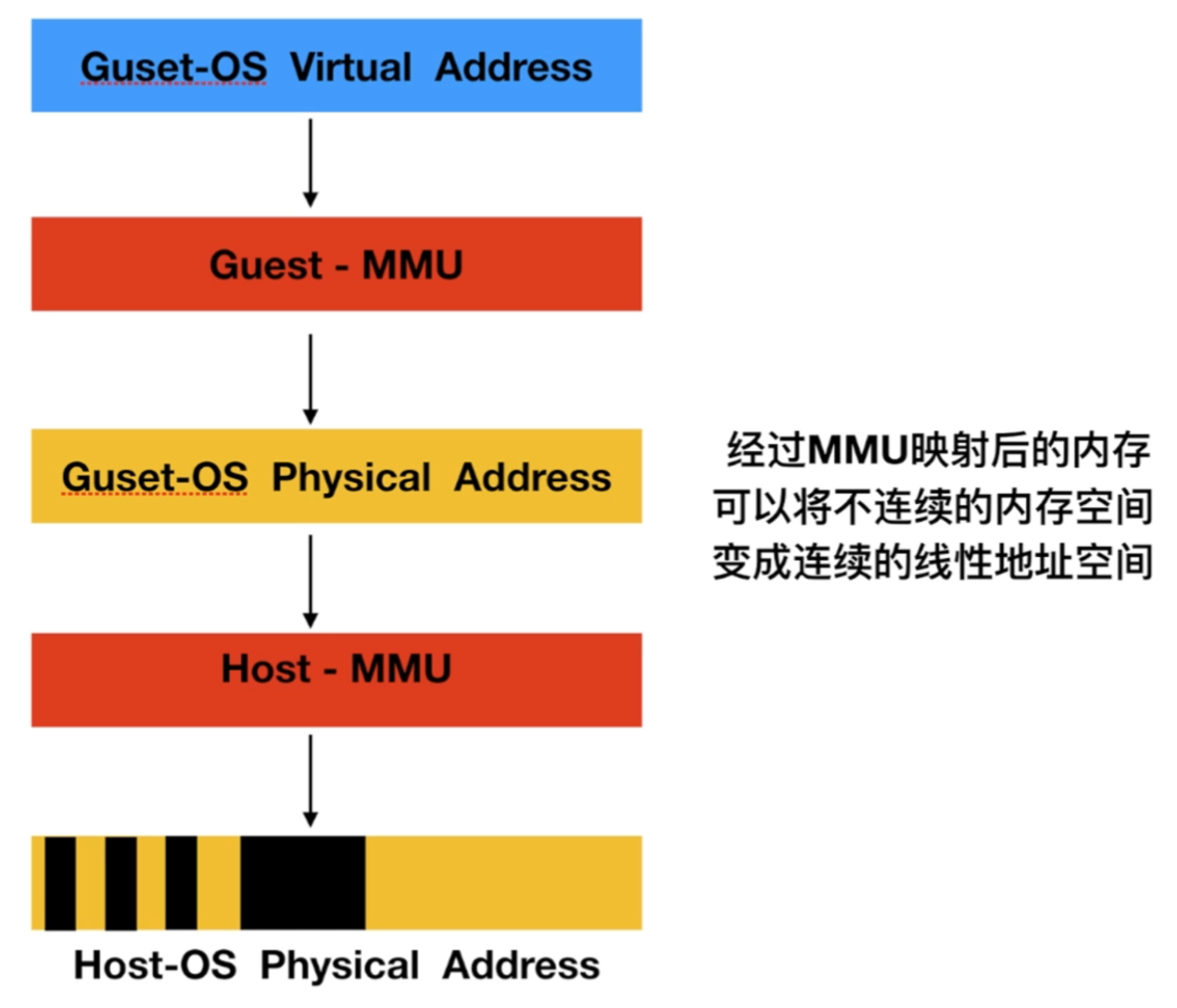
内存硬件虚拟化
在CPU中单独开辟一段空间,用来进行MMU内存管理单元虚拟化,MMU内存管理单元虚拟化可以实现映射表建立管理
直接将GVA虚机内存地址映射到HPA物理机内存地址
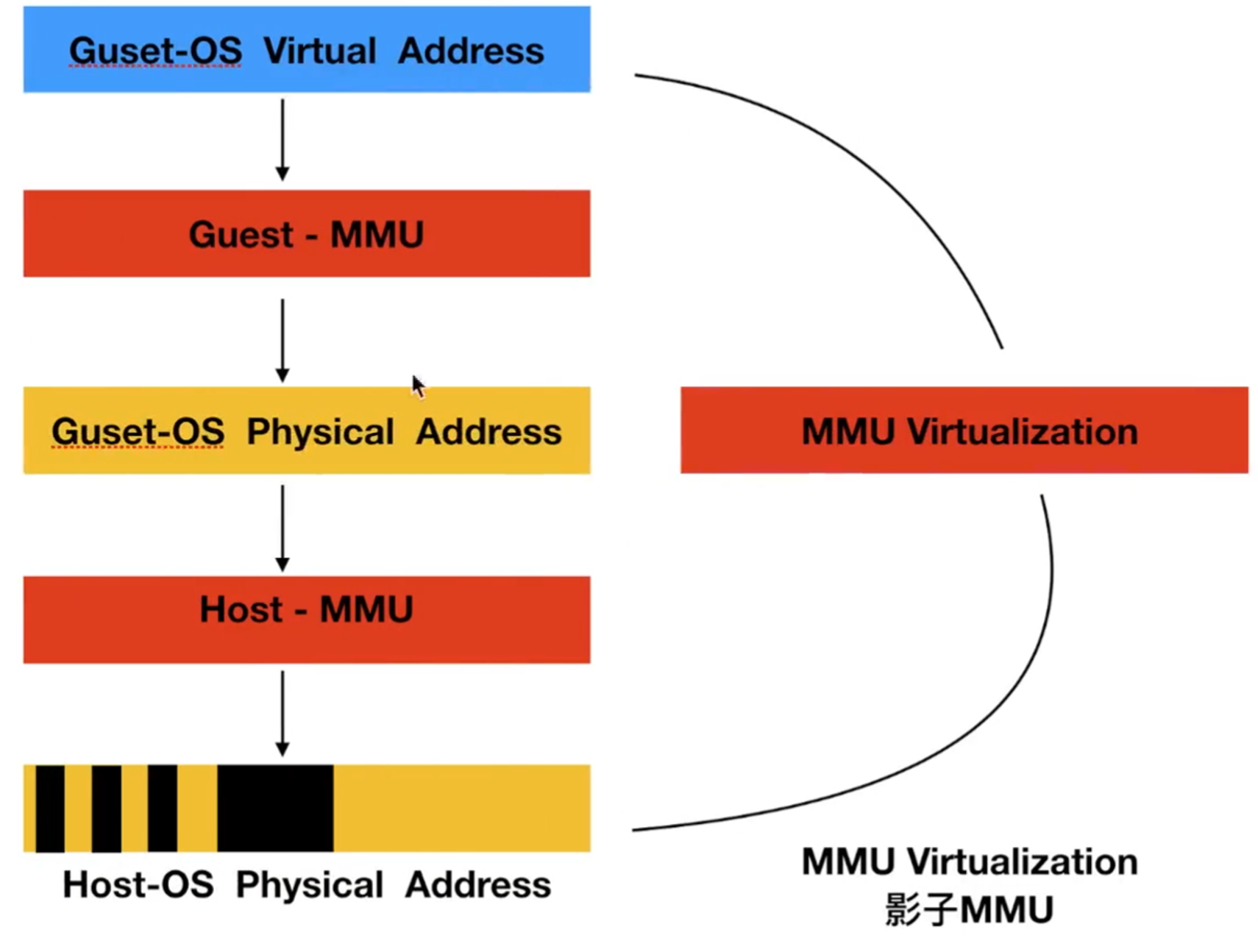
intel (EPT-Extension Page Table)——扩展内存页表(影子页表)
AMD(NPT/RVI)-比较垃圾

IO虚拟化
IO虚拟化的内容包括虚拟网卡、虚拟USB、虚拟磁盘。
IO虚拟化的通用问题:
1.设备发现
2.访问截获,并且能够进行正确翻译
在操作系统中,设备想要进行IO调用,需要用户态进程system call给内核,内核再找CPU进行读写
或通过DMA(内存和IO设备直接交互)
IO全虚拟化
VM的kernal找到VMM,VMM找宿主机的kernal调用
Emulator仿真技术:(VMware、Qemu)
把底层的IO设备,仿真成一个虚拟设备
Native-Device-Model – 原生设备模型 – 提供通用I/O设备(所有系统可以通过默认驱动进行识别,无需安装额外的驱动)
Native-back-Driver – (VMM端)原生后端驱动,调用Emulator仿真的虚拟设备
Native-front-Driver – (VM端)原生前端驱动 – 不需要进行额外独立安装的驱动类型
虚拟机如果通过原生前端驱动访问虚拟设备过程,针对虚拟机来讲和访问物理设备过程相同。
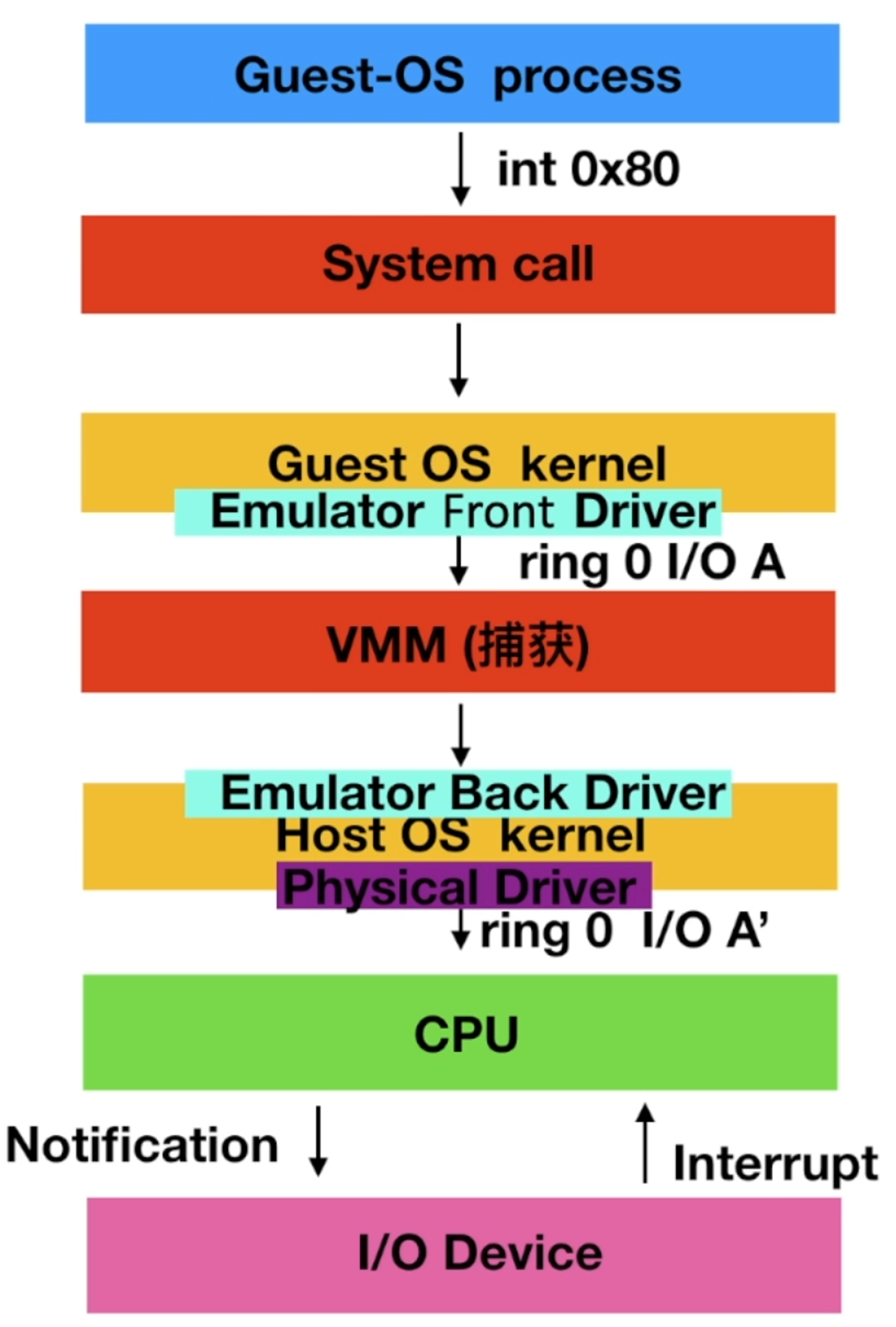
KVM I/O全虚拟化
- 用软件(qemu)完全模拟一个特定的设备
- 每次IO操作需要捕捉
- 不影响虚拟机本身
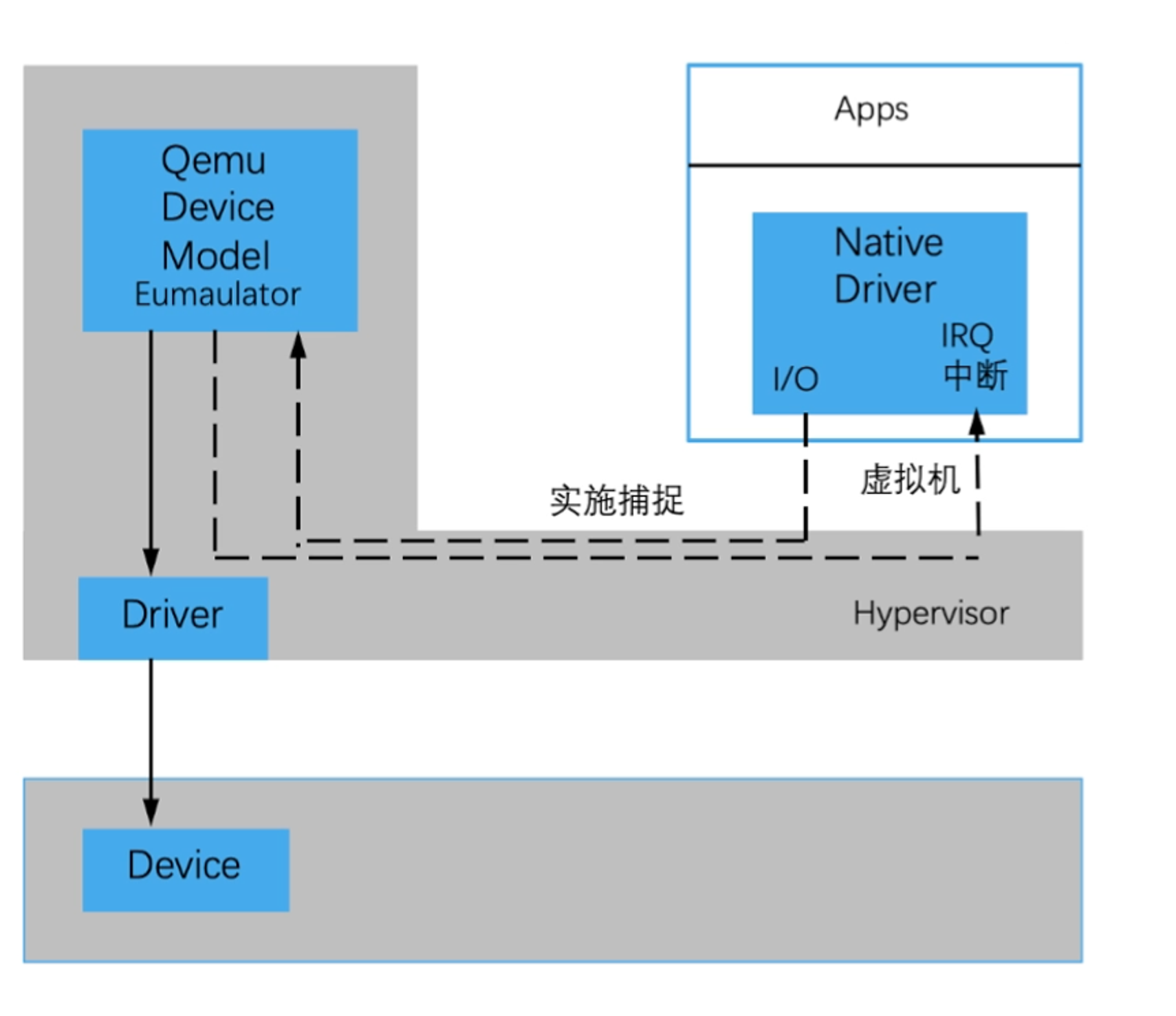
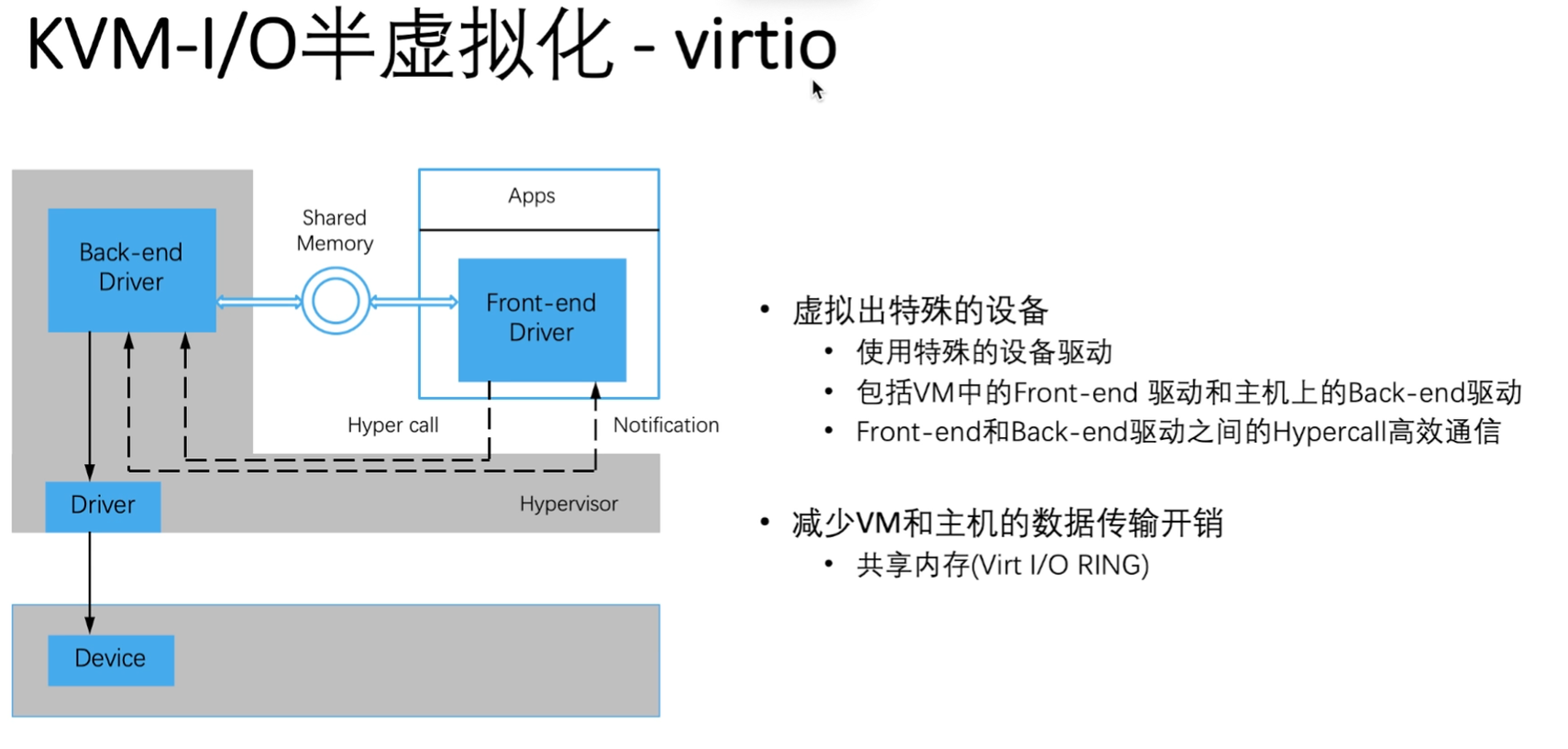
IO半虚拟化
半虚拟化前后端驱动对接 +单独额外提供I/O环
IO环是一段共享内存,可以由虚拟机和物理机同时访问
经典技术:
XEN(para virtualization)
在XEN中,有一个特殊虚机Domain0,是XEN的管理虚拟机(半虚拟化IO的后端驱动),集成了硬件驱动。通过IO环完成Domain0和普通VM信息交互
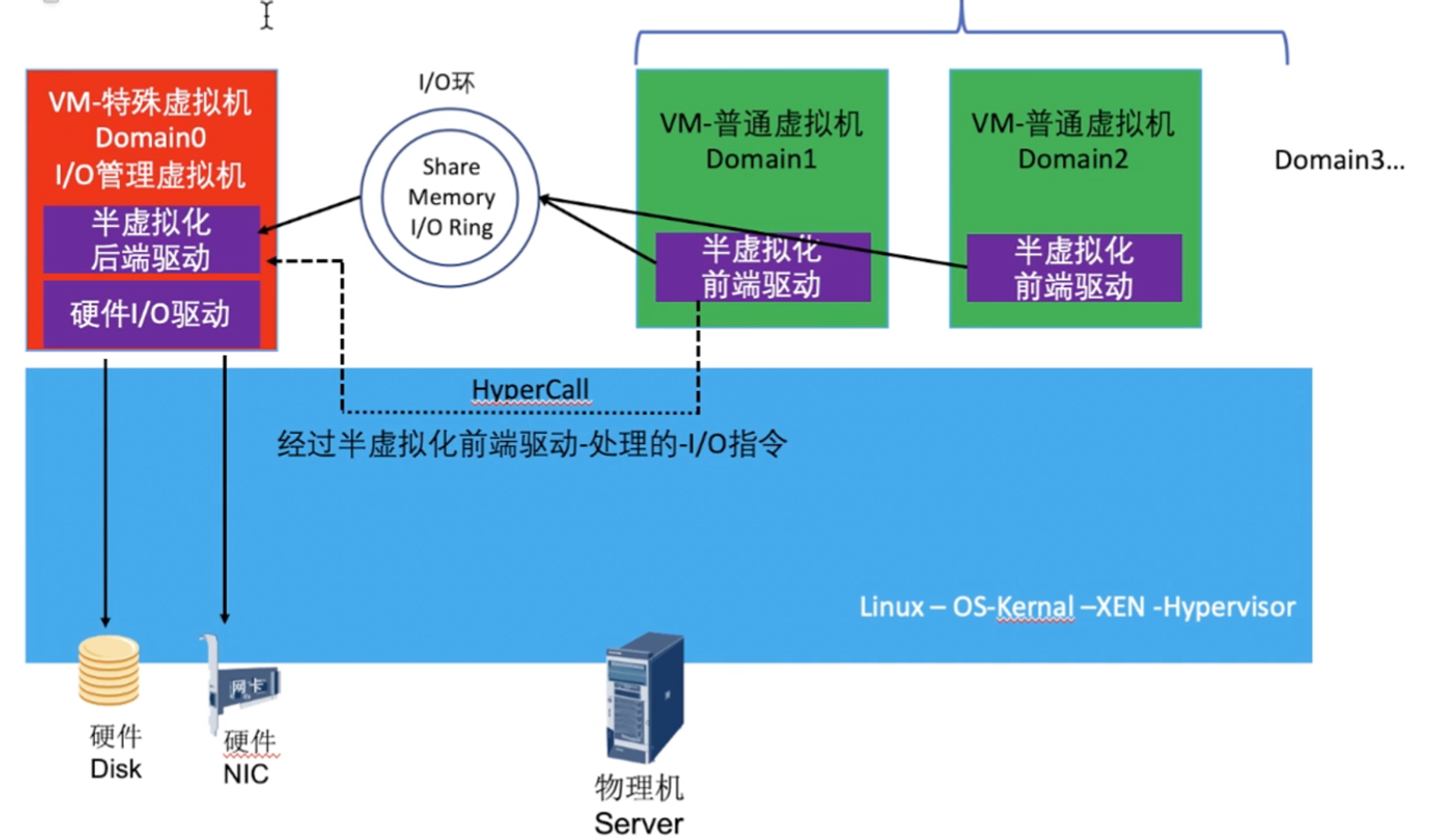
KVM (virtI/O半虚拟化)
和XEN的半虚拟化原理几乎一样
VMware I/O半虚拟化升级——vmxnet
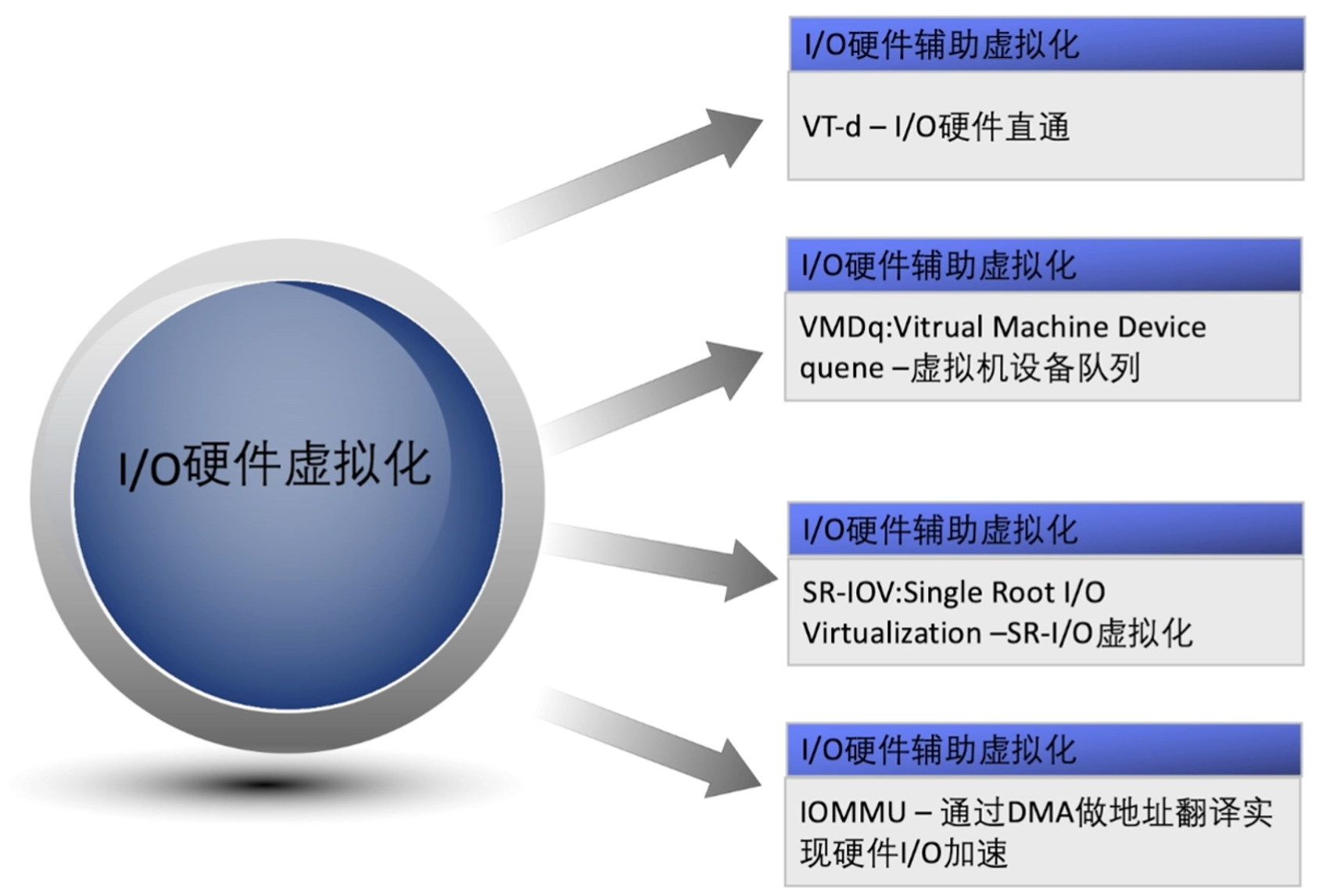
I/O硬件辅助(直通)虚拟化Passthrough
在虚拟机中直接安装硬件驱动,直接访问物理硬件达到高速访问效果
存储虚拟化
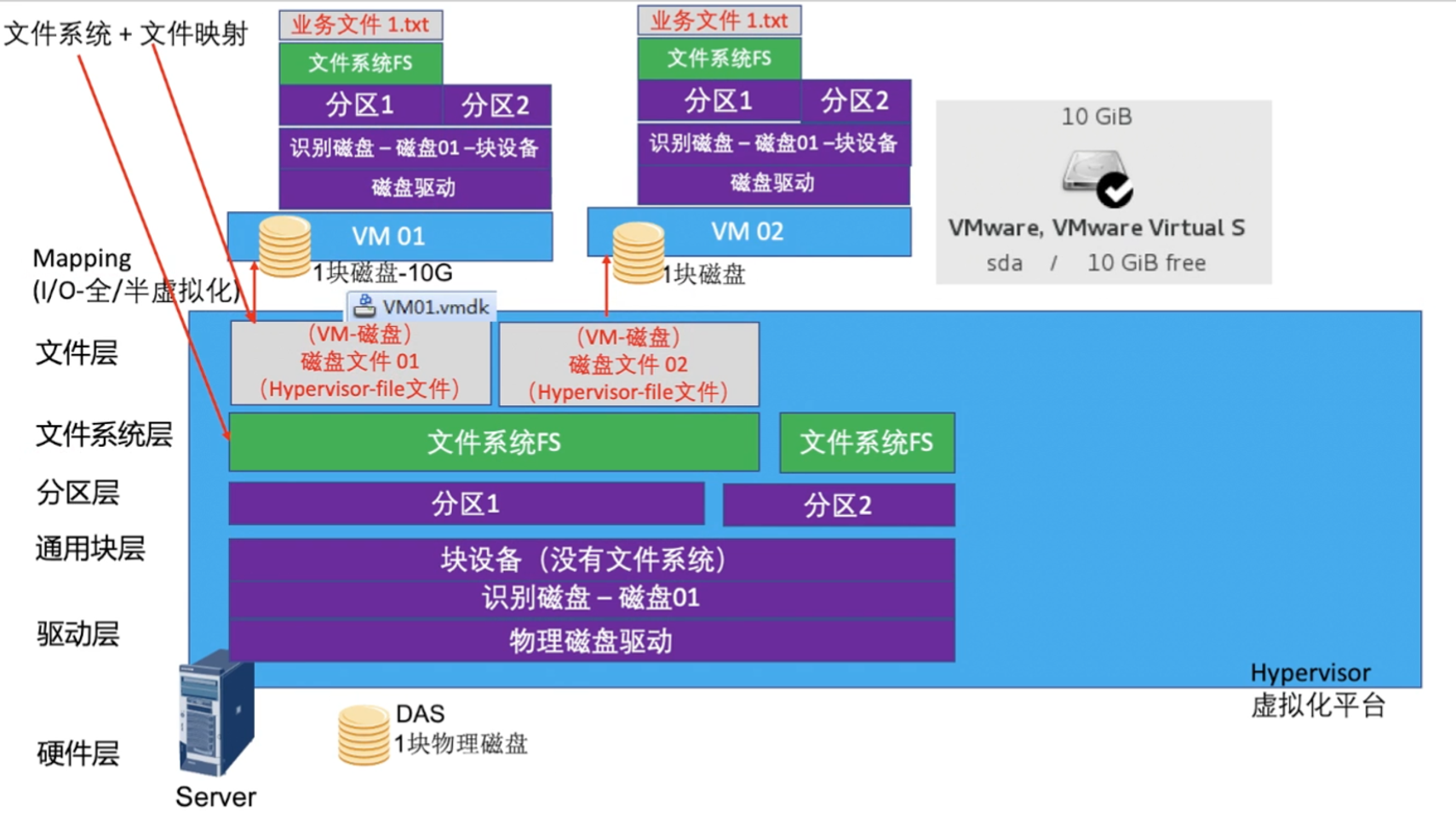
虚拟磁盘的实现方式
- 文件系统+文件映射
- 分区映射
- 裸设备映射
性能 :
裸设备映射 > 分区映射> 文件系统+文件映射
灵活性
裸设备映射 < 分区映射< 文件系统+文件映射
VMware(vsphere esxi | workstation)环境中 虚拟机配置文件格式为vmx
在KVM环境中,虚拟机配置文件格式为 XML
文件系统+文件映射
很好理解,将block设备安装文件系统之后,搞一个设备作为VM的虚拟磁盘
文件类型不同虚拟化平台中格式不同
VMware - 磁盘文件格式VMDK (Virtual Meachine DisK)
其他平台 (QCOW – img / QCOW2 / VHD. Virtual Hard Disk ..)
虚拟绑定是一个磁盘文件
分区映射
分区映射 | 虚拟机绑定 物理磁盘中的分区
将block设备分区后,将该分区直接分配给VM
裸设备映射
直接把block设备绑定给VM