总体思路:filebeat生产→kafka topic→logstash消费、格式转换→es→kibana
zookeeper简单介绍 zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小
Zookeeper主要作用在于:
1.节点选举
主节点挂了之后,从节点就会接手工作 ,并且,保证这个节点是唯一的,从而保证集群的高可用
2.统一配置文件管理
只需要部署一台服务器
则可以把相同的配置文件,同步更新到其他所有服务器,比如,修改了Hadoop,Kafka,redis统一配置等
3.发布与订阅消息
类似于消息队列,发布者把数据存在znode节点上,订阅者会读取这个数据
4.集群管理
集群中保证数据的一致性
Zookeeper的选举机制===>过半机制
安装的台数===>奇数台(否则无法过半机制)
一般情况下10台服务器需安装ZK3台 (华为FusionStorage平台在OSD组件仲裁的时候用的也是ZK)
20台======>5台
50台=======>7台
100台=======>11台
zookeeper角色:
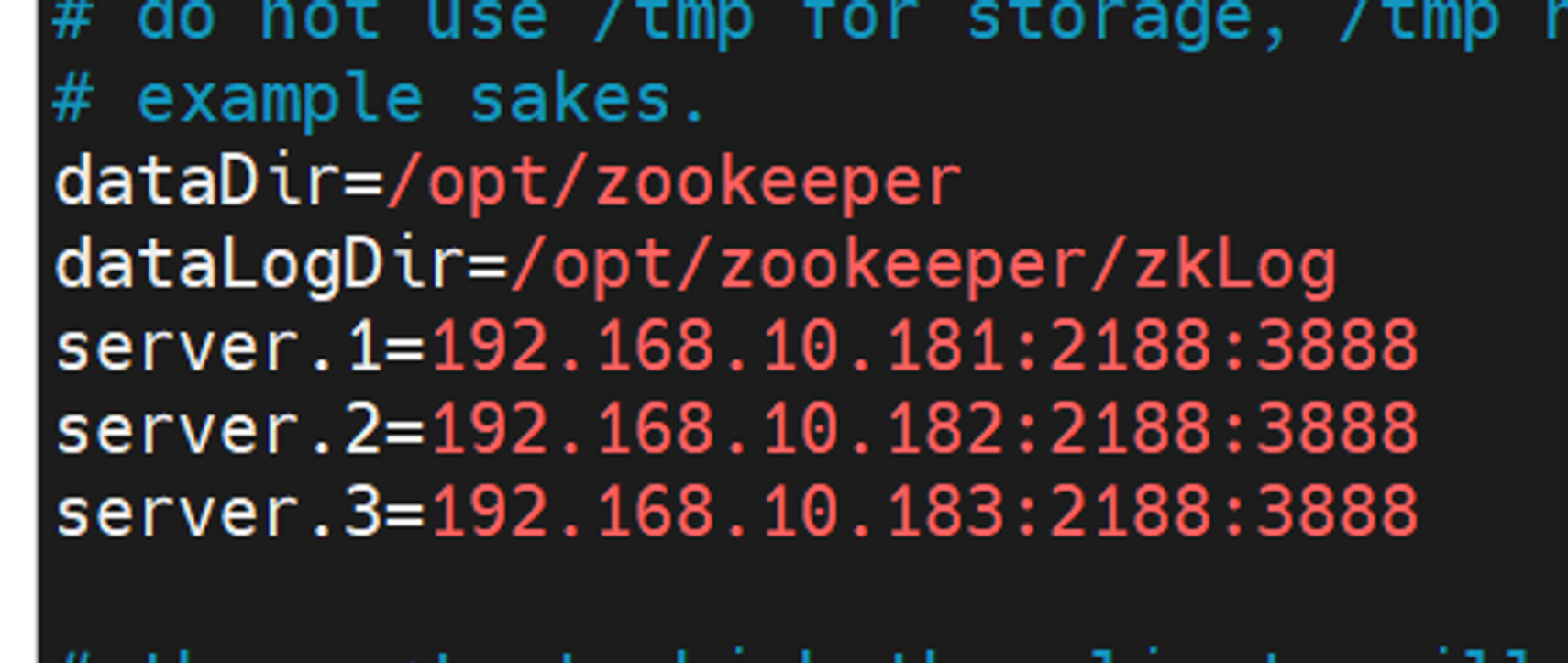
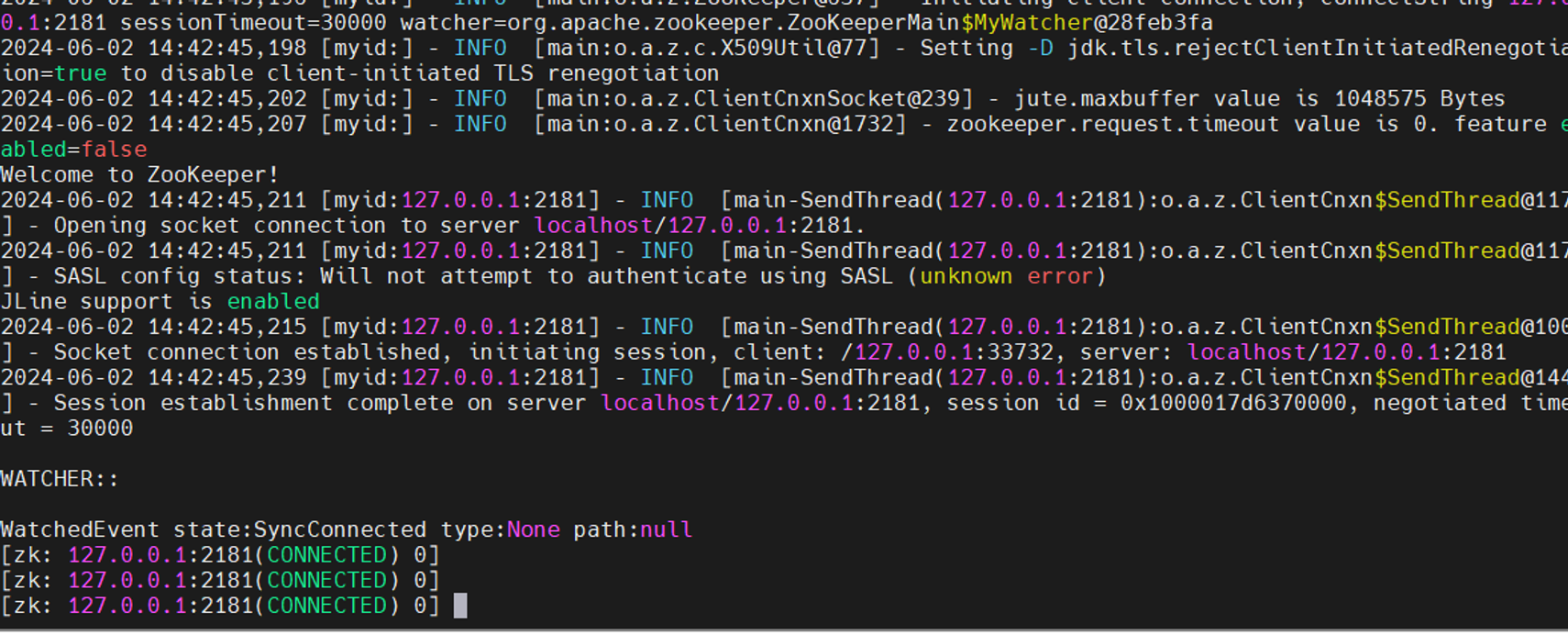
部署zookeeper集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 环境: centos7.9 8C8G 50Gdisk 192.168.10.181 zoo1 192.168.10.182 zoo2 192.168.10.183 zoo3 filebeats版本7.13.1 kafka版本3.1.0 zookeeper版本3.8 logstash版本7.9.2 hostnamectl set-hostname zoo1 && bash nmcli con modify ens18 ipv4.addresses 192.168.10.181/24 ipv4.dns 192.168.1.1 ipv4.gateway 192.168.10.1 ipv4.method manual nmcli con up ens18 hostnamectl set-hostname zoo2 && bash nmcli con modify ens18 ipv4.addresses 192.168.10.182/24 ipv4.dns 192.168.1.1 ipv4.gateway 192.168.10.1 ipv4.method manual nmcli con up ens18 hostnamectl set-hostname zoo3 && bash nmcli con modify ens18 ipv4.addresses 192.168.10.183/24 ipv4.dns 192.168.1.1 ipv4.gateway 192.168.10.1 ipv4.method manual nmcli con up ens18 cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.181 zoo1 192.168.10.182 zoo2 192.168.10.183 zoo3 scp /etc/hosts zoo1:/etc/hosts scp /etc/hosts zoo2:/etc/hosts scp /etc/hosts zoo3:/etc/hosts sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0 systemctl disable firewalld --now yum -y install chrony sed -i 's/^server/#server/g' /etc/chrony.conf sed -i '1s/^/server cn.pool.ntp.org iburst\n/' /etc/chrony.conf systemctl restart chronyd tar zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt/ mv /opt/apache-zookeeper-3.8.0-bin/ /opt/zookeepermkdir /opt/zookeeper/zkDatamkdir /opt/zookeeper/zkLog指定数据目录与日志目录,指定另外几个节点的IP: cd /opt/zookeeper/conf/cp zoo_sample.cfg zoo.cfgvim zoo.cfg 传送到另外两个节点: scp zoo.cfg zoo1:/opt/zookeeper/conf/ scp zoo.cfg zoo2:/opt/zookeeper/conf/ scp zoo.cfg zoo3:/opt/zookeeper/conf/ 安装java yum -y install java 设置三台的myid zoo1: echo 1 > /opt/zookeeper/myidzoo2: echo 2 > /opt/zookeeper/myidzoo3: echo 3 > /opt/zookeeper/myid123依次启动 cd /opt/zookeeper/binnohup ./zkServer.sh start ../conf/zoo.cfg &测试 cd /opt/zookeeper/bin/./zkCli.sh -server 127.0.0.1:2181 注意必须关闭安全设置和时钟同步,我一开始没有设置直接一堆报错
部署kafka集群 kafka基础概念
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer:负责发布消息到Kafka broker
Consumer:消息消费者,向Kafka broker读取消息的客户端。
和zk的关系
zookeeper可以帮助kafka管理broker、consumer。kafka在创建Broker后,向zookeeper注册新的broker信息,实现在服务器正常运行下的水平拓展。
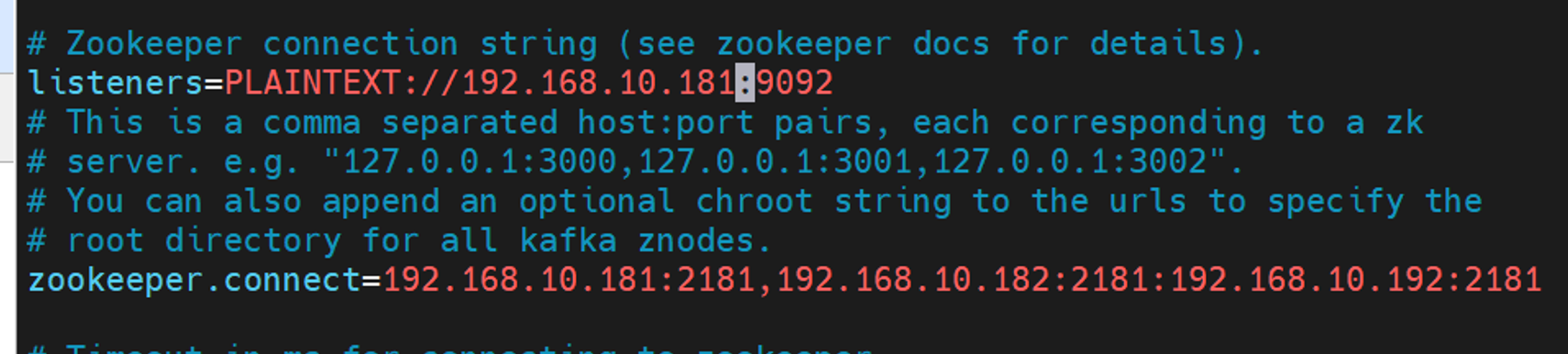
1 2 3 4 5 6 tar xf kafka_2.13-3.1.0.tgz 修改配置文件 vim kafka_2.13-3.1.0/config/server.properties listeners=192.168.10.181://:9092 zookeeper.connect=192.168.10.181:2181,192.168.10.182:2181:192.168.10.192:2181
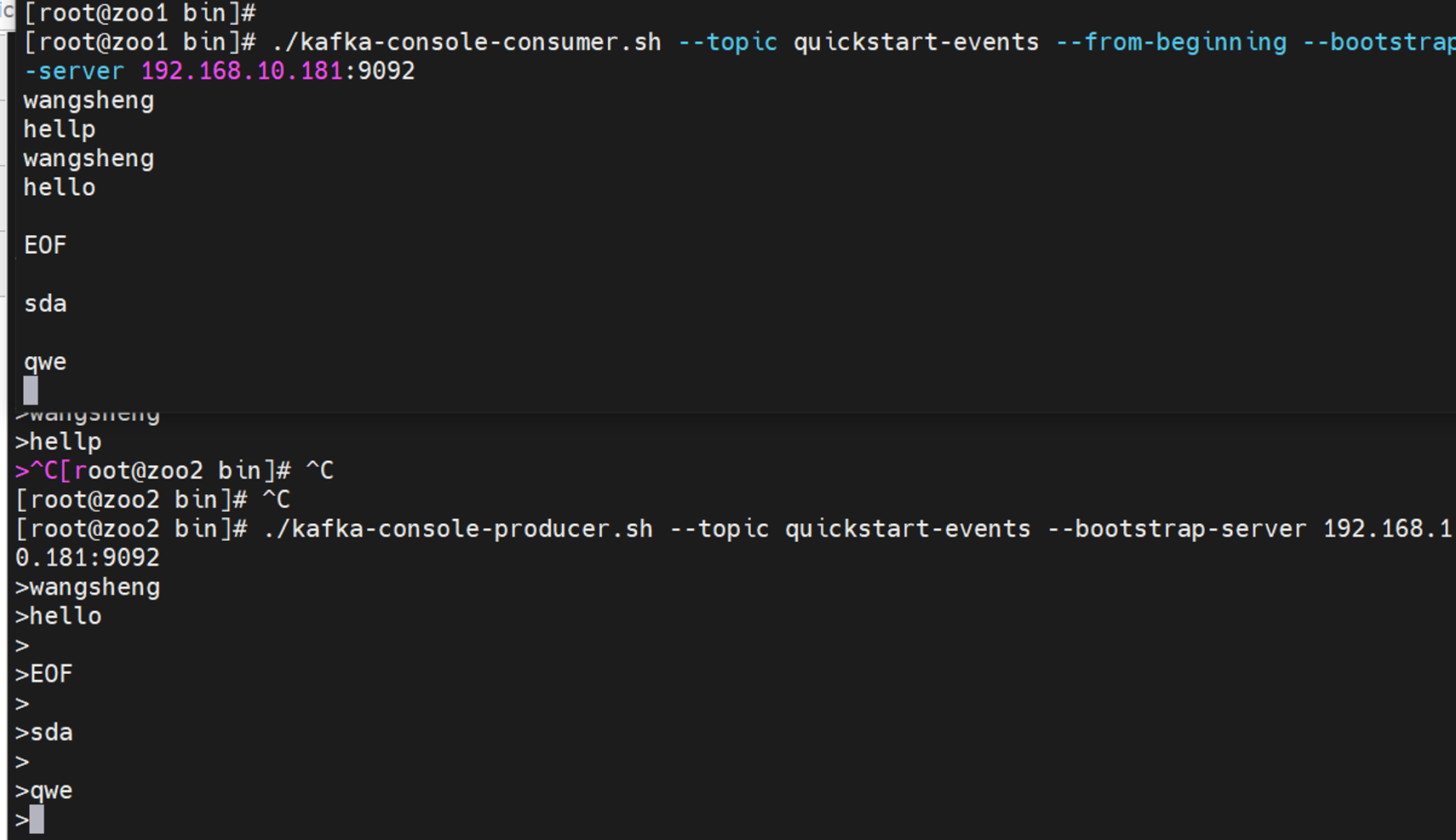
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 启动kafka cd kafka_2.13-3.1.0/bin./kafka-server-start.sh -daemon ../config/server.properties 测试————登录zookeeper,查看信息broker/ids /opt/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181 [zk: 127.0.0.1:2181(CONNECTED) 0] ls /brokers/ids [0] 测试————生产者消费者模型 1.kafka里创建topic cd kafka_2.13-3.1.0/bin./kafka-topics.sh --create --topic quickstart-events --bootstrap-server 192.168.10.181:9092 2.查看topic ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server 192.168.10.181:9092 3.调用生产者console向topic中写入消息 ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server 192.168.10.181:9092 4.同时调用消费者读取消息 ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server 192.168.10.181:9092
多节点做集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 将文件夹直接复制过去 scp -r kafka_2.13-3.1.0/ zoo2:~ scp -r kafka_2.13-3.1.0/ zoo3:~ 修改server.properties配置文件,将其中的kafka监听IP改成本机ip vim kafka_2.13-3.1.0/config/server.properties listeners=PLAINTEXT://192.168.10.182:9092 listeners=PLAINTEXT://192.168.10.183:9092 修改server.properties配置文件,修改broker.id 不能都为0,因为broker.id是kafka物理服务器的标识 broker.id=1 broker.id=2 启动kafka cd /root/kafka_2.13-3.1.0/bin./kafka-server-start.sh -daemon ../config/server.properties 本机查看kafka是否正常运行 ps aux | grep kafka 登录zookeeper查看 /opt/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181 [zk: 127.0.0.1:2181(CONNECTED) 0] ls /brokers/ids [0, 1, 2]
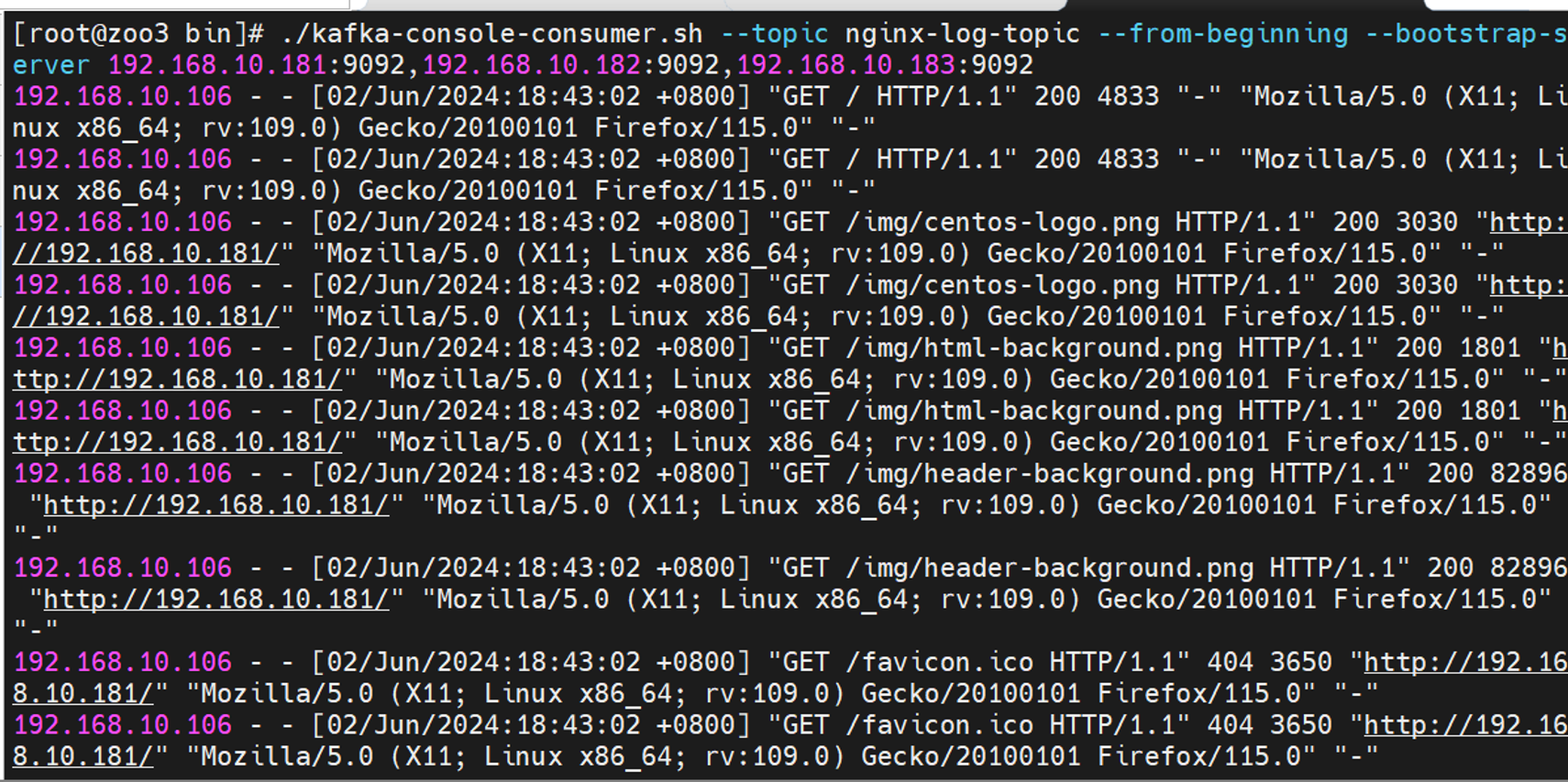
部署filebeat服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 1.安装一个nginx用来被采集日志,先单节点采集,后面再多节点 yum -y install nginx systemctl enable nginx.service --now 2.kafka创建topic,存放日志数据,指定kafka主机IP/端口 cd kafka_2.13-3.1.0/bin/./kafka-topics.sh --create --topic nginx-log-topic --bootstrap-server 192.168.10.181:9092,192.168.10.182:9092,192.168.10.183:9092 查询topic ./kafka-topics.sh --describe --topic nginx-log-topic --bootstrap-server 192.168.10.181:9092 3.为nginx主机下载解压filebeat,版本7.13.1 wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.1-linux-x86_64.tar.gz tar xf filebeat-7.13.1-linux-x86_64.tar.gz 4.开启filebeat的nginx模块 ./filebeat modules enable nginx 5.写一个filebeats_nginx.yaml配置文件 vim filebeats_nginx.yaml filebeat.modules: - module: nginx access: enabled: true var.paths: ["/var/log/nginx/access.log*" ] error: enabled: true var.paths: ["/var/log/nginx/error.log*" ] output.kafka: enabled: true hosts: ['192.168.10.181:9092' , '192.168.10.182:9092' ,'192.168.10.183:9092' ] topic: 'nginx-log-topic' required_acks: 1 compression: gzip max_message_bytes: 1000000 codec.format: string: '%{[message]}' 6.启动filebeat nohup ./filebeat -e -c filebeats_nginx.yaml7.测试 尝试消费一下————查看kafka的topic是否有日志 cd ~/kafka_2.13-3.1.0/bin/./kafka-console-consumer.sh --topic nginx-log-topic --from-beginning --bootstrap-server 192.168.10.181:9092,192.168.10.182:9092,192.168.10.183:9092 登录一下nginx界面 能看到有数据,说明topic已经成功通过filebeat作为生产者存入数据了
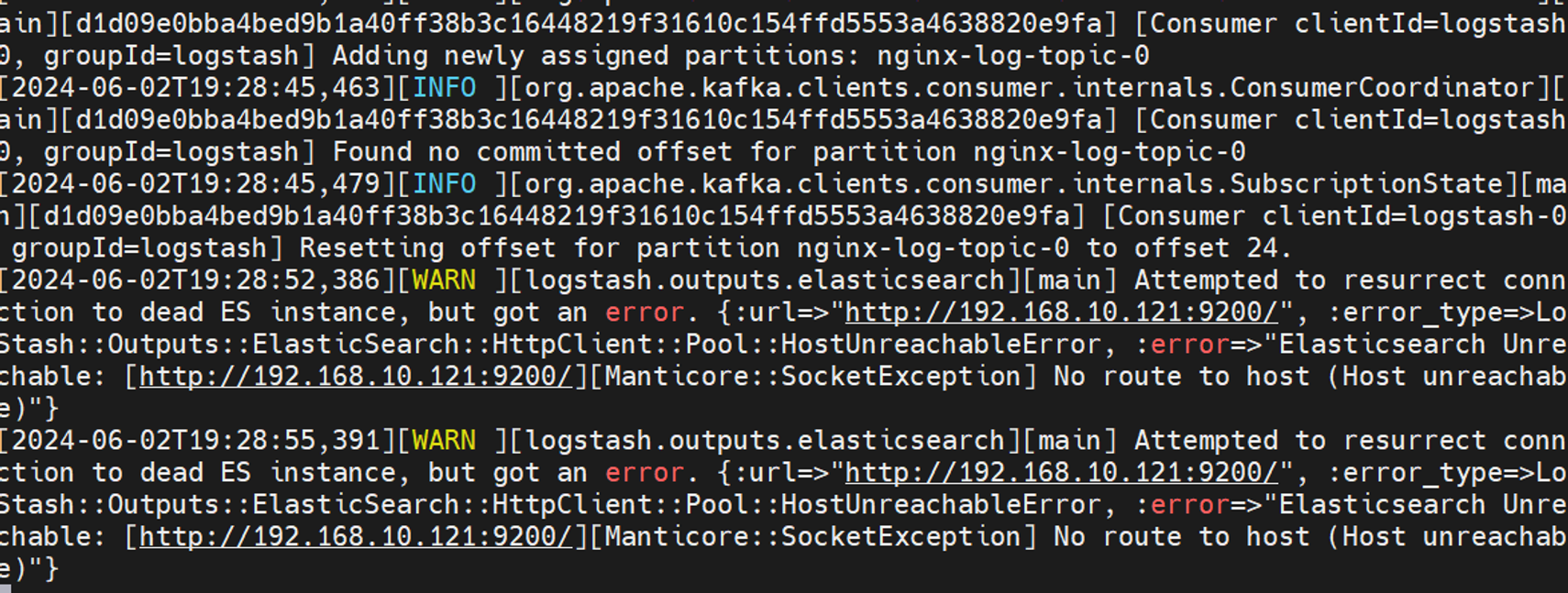
部署logstash 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 logstash版本7.9.2 1.下载与解压 wget https://artifacts.elastic.co/downloads/logstash/logstash-7.9.2.tar.gz tar xf logstash-7.9.2.tar.gz cd logstash-7.9.2/2.创建一个配置文件nginx.conf 配置input模块,设置从kafka消费 cat > config/nginx.conf << EOF input{ kafka { bootstrap_servers => ["192.168.10.181:9092,192.168.10.182:9092 ,192.168.10.183:9092"] auto_offset_reset => "latest" consumer_threads => 3 decorate_events => true topics => ["nginx-log-topic"] codec => "json" } } output { elasticsearch { hosts => ["192.168.10.181:9200"] index => "kafkalog-%{+YYYY.MM.dd}" } } EOF 注释部分: input { kafka { bootstrap_servers => ["192.168.10.181:9092,192.168.10.182:9092,192.168.10.183:9092" ] auto_offset_reset => "latest" consumer_threads => 3 decorate_events => true topics => ["nginx-log-topic" ] codec => "json" } } output { elasticsearch { hosts => ["192.168.10.121:9200" ] index => "kafkalog-%{+YYYY.MM.dd}" } } 3.启动logstash cd /root/logstash-7.9.2/binnohup ./logstash -f ../config/nginx.conf >> logstash.log &此时会报错,因为咱还没有安装es,自然9200端口是不通的
部署es与kibana服务 elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。elasticsearch具有三大功能:搜索、分析、存储数据
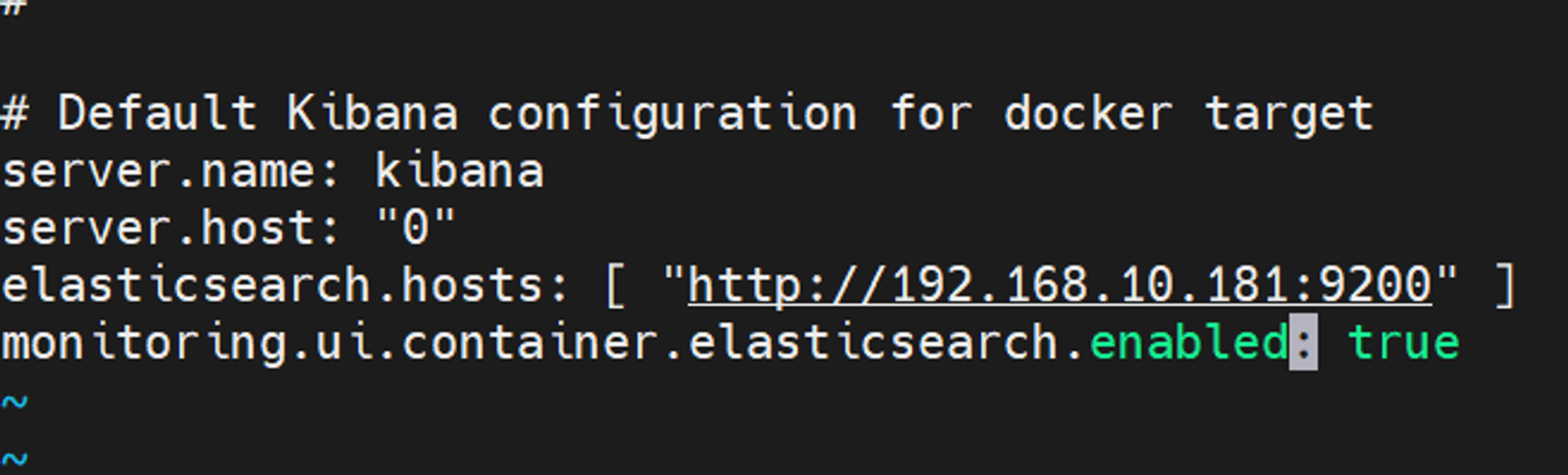
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 采用容器化的方式使用es,版本7.9.2 1.创建一个目录用来存es的数据 mkdir -p ~/es_datachmod 777 ~/es_data2.安装与配置docker yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum -y install docker-ce cat > /etc/docker/daemon.json << EOF { "registry-mirrors": [ "https://hub-mirror.c.163.com", "https://docker.m.daocloud.io", "https://ghcr.io", "https://mirror.baidubce.com", "https://docker.nju.edu.cn"] } EOF systemctl daemon-reload systemctl enable docker --now systemctl restart docker 3.容器化部署es7.9.2 docker run -p 9200:9200 -p 9330:9300 -itd -e "discovery.type=single-node" --name es -v /es_data:/sr/share/elasticsearch/data docker.io/library/elasticsearch:7.9.2 docker ps netstat -tunlp | grep 9200 tcp 0 0 0.0.0.0:9200 0.0.0.0:* LISTEN 18151/docker-proxy 4.容器化部署kibana7.9.2 docker run -p 5601:5601 -it -d --link es -e ELASTICSEARCH_URL=http://192.168.10.181:9200 --name kibana kibana:7.9.2 docker ps | grep kibana ss -tunlp | grep 5601 5.修改kibana配置文件kibana.yml docker exec -it kibana /bin/bash vi config/kibana.yml 修改es地址为实际地址 exit docker restart kibana
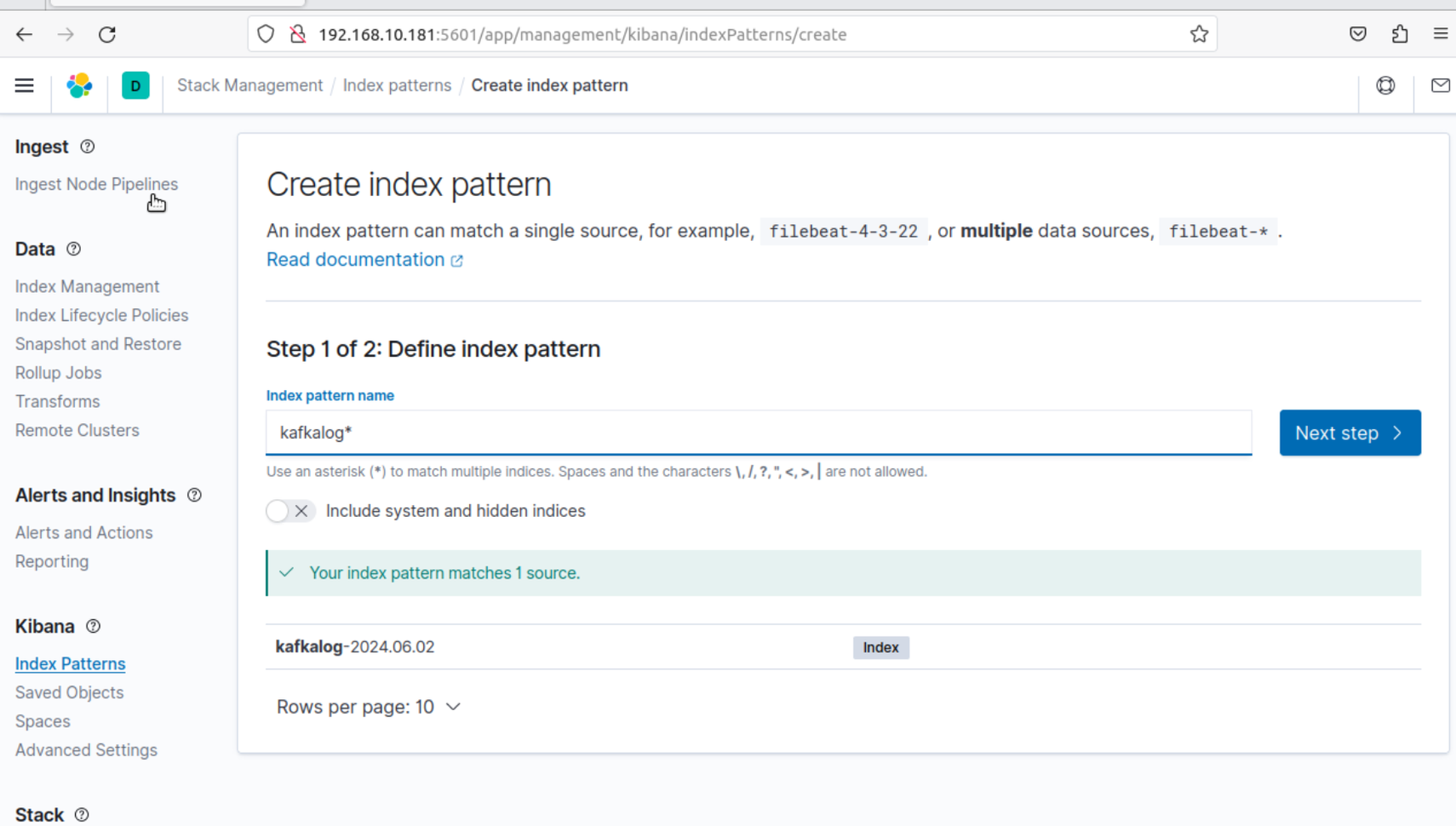
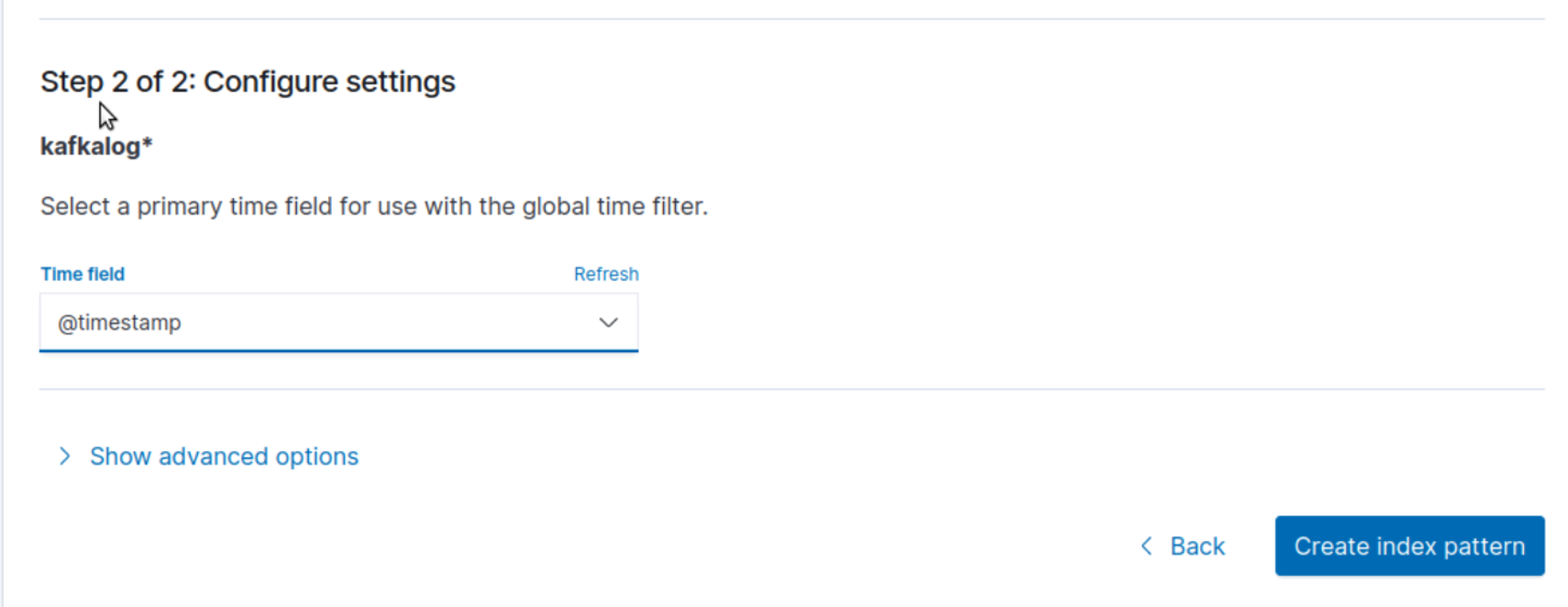
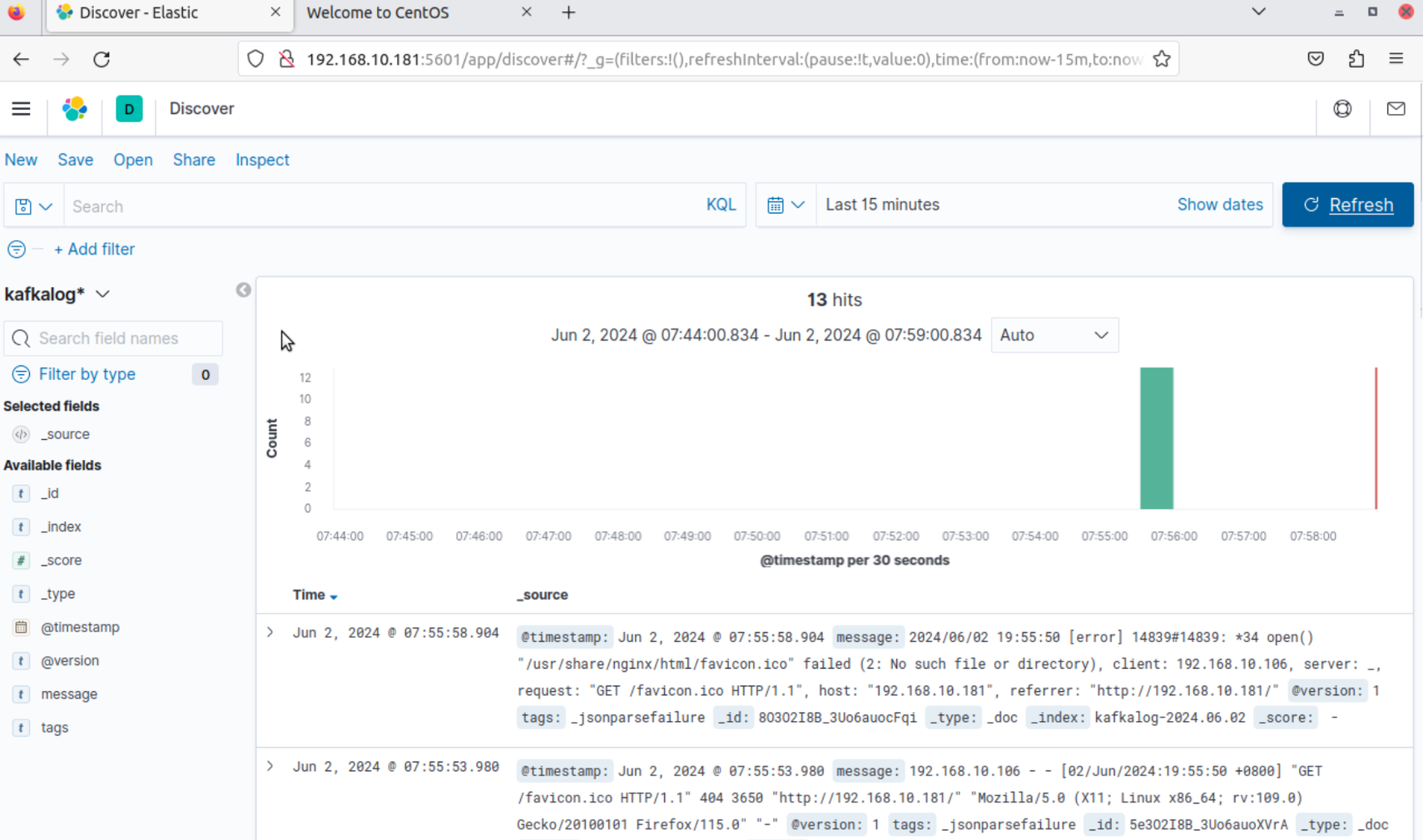
1 2 3 6.登录kibana界面 端口为5601 创建匹配刚刚创建模式的索引
这里忘记给容器做时间同步了,所以时间有点早。