如果出现无法载图的情况,请检查与github的连通性
概要 官网docs.ceph.com
特点:
ceph基本结构
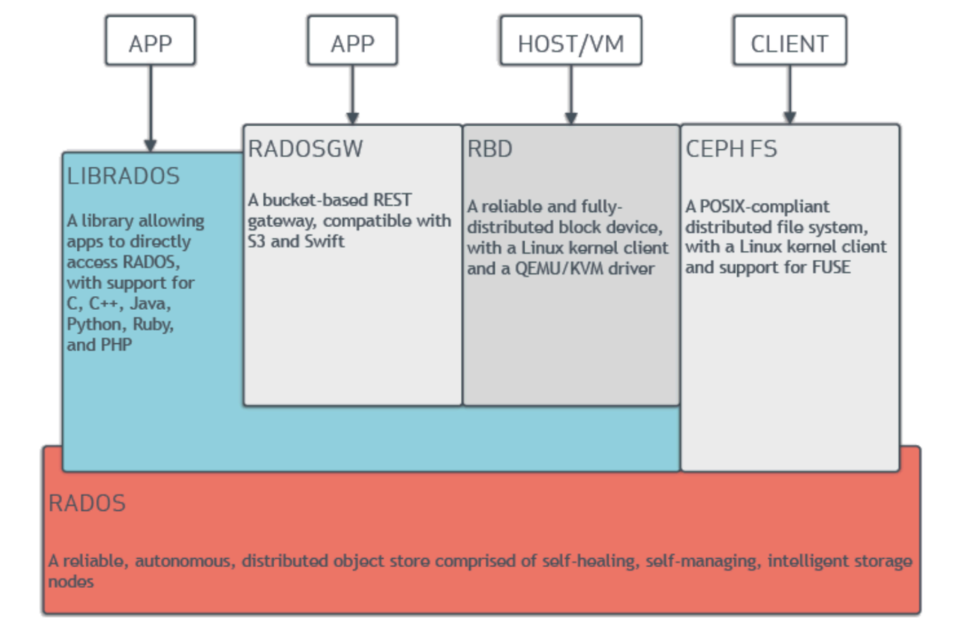
1.RADOS,全称是”可靠性⾃动化分布式对象存储(Reliable Autonomic Distributed Object Store)”,是Ceph集群的基础,RADOS负责Ceph中的所有数据都以对象形式存储。ceph通过RADOS层提供数据⼀致性、可靠性,数据迁移,数据再平衡等⾼级底层特性。
2.librados是rados的底层函数库 ,⽤作实现作为”RBD、RGW”的基础,可以为Ceph FS提供POSIX接⼝,librados⽬前⽀持PHP、Ruby、Java、Python、C和C++语⾔,⽤来简化RADOS层的访问,并且提供librados API
3.RBD (RBD,RADOS Block Device),也叫Ceph块设备,原先叫做RADOS块设备,对外提供块存储,它可以像祼磁盘⼀样被映射、格式化、挂载到操作系统上,在云平台中实现云硬盘功能的底层服务。
4.RGW (RADOS GW),Ceph对象⽹关,简称为RGW,⽬前对Amazon S3和OpenStack对象存储API提供了兼容的Restful API接⼝,可以实现与openstack swift或者Amazon S3类似的对象存储服务。
5.Ceph FS,Cehp⽂件系统,提供了⼀个任意⼤⼩且兼容POSIX的分布式⽂件系统,可以⽀持FUSE。ceph FUSE(Filesystem in Userspace) 是指 Ceph ⽂件系统的⼀个⽤户态⽂件系统客户端,它允许”⾮特权⽤户以⽤户态程序的⽅式创建和管理⽂件系统”,⽽⽆需修改内核代码。”⾮特权⽤户以⽤户态程序的⽅式创建和管理⽂件系统”是指允许⽤户挂载 Ceph ⽂件系统(CephFS),直接运⾏在⽤户空间中,⽐内核挂载具有更强的稳定性和安全性。不过,由于 FUSE 是在⽤户空间运⾏,通常它的性能会略低于内核客户端。
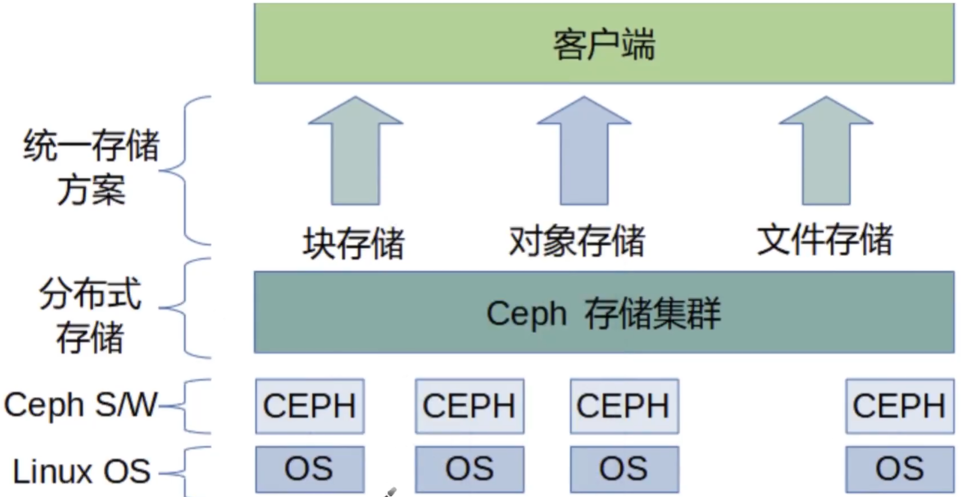
ceph存储组件框架
Ceph基于RADOS提供了⼀个可扩展的、可靠的存储集群存储服务,Ceph存储集群由多种类型的守护程序组成:
类比:
ceph OSD 与fusionstorage的差不多
OSD,Ceph对外存储设备,负责数据读写操作,真正存储⽤户数据的组件,⼀个OSD守护进程与集群的⼀个物理磁盘绑定,每⼀块磁盘对应⼀个OSD守护进程,⼀个主机由⼀个或多个 osd 组成。
⼀般来说,⽤于部署Ceph集群物理机中的磁盘数量与OSD守护进程数量是⼀样的。
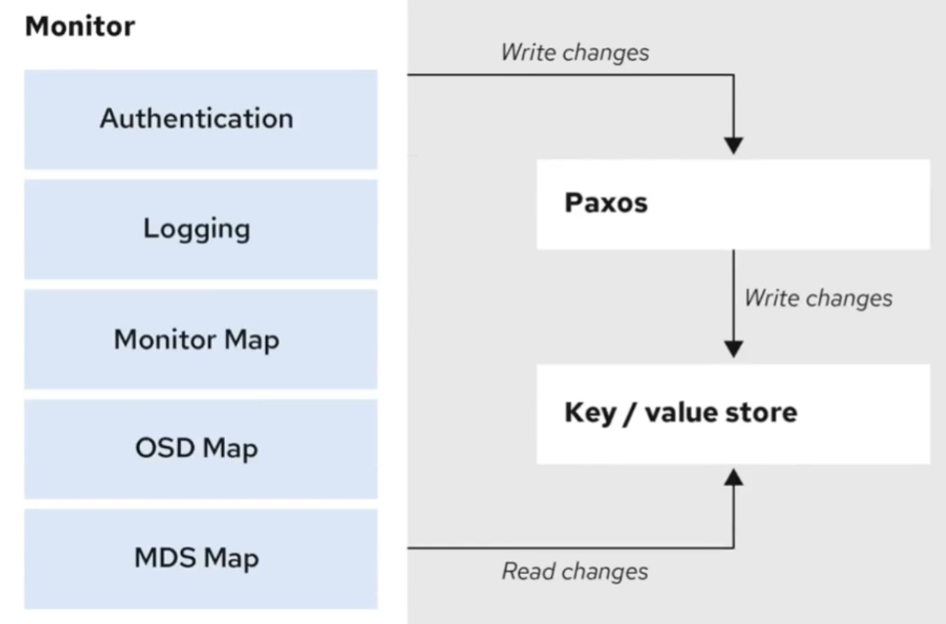
ceph monitor
MON , Ceph的monitor组件,负责维护ceph的集群状态,ceph将集群的状态保存在⼏个map结构⾥,如OSD、MON、PG和CRUSH,集群内所有的节点都向MON组件上报信息⽤于维护集群状态映射,monitor将每⼀个组件将上报的状态信息存储在不同的map⾥,monitor不存储实际的数据,只存储集群状态信息。 数据读写时,不通过MON。
Ceph维护集群状态是通过跟踪集群中所有其他守护进程的状态和元数据,包括监控守护进程、管理守护进程、对象存储守护进程(OSDs),以及元数据服务器(MDSs)。
Ceph集群映射包括监控映射、OSD映射、PG(Placement Group)映射和CRUSH(Controlled Replication Under Scalable Hashing)映射。这些映射对于数据的分布和复制⾮常重要。
Ceph 客户端与Ceph Monitors 交互以获取集群映射和身份验证信息。⼀旦客户端有了这些信息,它们就可
在 Ceph 集群中,Ceph Monitors 形成⼀个仲裁集群 ,以保持集群的⼀致性和⾼可⽤性。为了避免脑裂(Split-brain)情况,Monitors 使⽤基于 Paxos 的协议来达成⼀致。在Ceph 中,Paxos 是确保集群元数据⼀致性的关键算法,它允许 Ceph Monitors 在出现故障和⽹络问题时,依然能够正确地管理集群状态。
Ceph Monitors 管理客户端和其他守护进程的身份验证,确保只有经过授权的服务和⽤户才能访问集群资源。
Ceph Monitors 提供了⼀个集中的配置服务,允许管理员为集群中的守护进程配置和调整运⾏时设置。
在⼀台服务器上只部署⼀个 Ceph Monitor。为了保证⾼可⽤性,通常建议部署奇数个 Ceph Monitors(如3、5或7个)。这样做是为了在投票过程中避免可能的平票情况(过半数),保证即使在部分 Ceph Monitors 失效的情况下集群仍然能够正常运⾏。
在⼀个⽣产环境的⾼可⽤ Ceph 集群中,建议⾄少部署三个Ceph Monitor 实例守护进程,并且这些实例应该分布在不同的物理服务器上。这样即使⼀台服务器宕机,其他的 Monitor 还能保持集群的正常运作,并保持quorum 仲裁可⽤状态。部署奇数个 Monitor 实例是为了避免在决策过程中出现平票的情况。
ceph MDS——文件系统的元数据 Ceph Metadata Server(Ceph MDS)是 Ceph ⽂件系统(CephFS)的关键组件,主要负责存储和管理⽂件系统的元数据。在 CephFS 中,数据本身被存储在对象存储设备(OSDs)中,⽽⽂件和⽬录的元数据(如⽂件名、⽬录结构、权限、时间戳等)则由 MDS元数据服务管理,为ceph ⽂件系统(NFS/CephFS)存储元数据,(即 Ceph 块设备和 Ceph 对象存储不使⽤MDS)
MDS 存储与⽂件相关的所有元数据信息。这包括⽂件名、⽬录结构、⼤⼩、权限、所有权以及其他⽂件属性。当⽤户执⾏⽂件操作(如 ls、find、mkdir)时,这些请求会被发送到 MDS,⽽不是 OSD。测试这样做可以显著提⾼性能,因为元数据操作通常远⽐实际的数据操作更频繁。
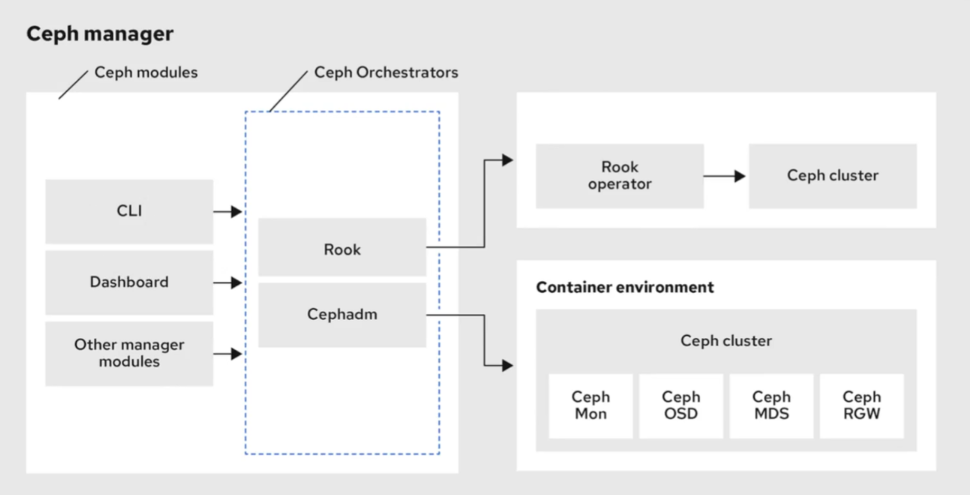
ceph Manager管理界面——提供dashboard
Ceph Manager (通常称为 ceph-mgr),ceph-mgr是在⼀个主机上运⾏的⼀个守护进程,Ceph Manager守护进程(ceph-mgr)负责跟踪运⾏时指标和Ceph集群的当前状态,包括存储利⽤率,当前性能指标和系统负载,主要职责是收集所有运⾏中的 Ceph 守护进程的运⾏时性能指标和状态信息。Ceph Manager 守护程序还托管基于 python 的模块来管理和公开 Ceph 集群信息,包括基于 Web 的 Ceph 仪表板和 REST API。
Ceph Manager 的主要功能包括:
ceph部署 环境说明 虚拟化操作系统PVE-8.1-2
192.168.10.141 ceph-node1
节点初始化配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 节点初始化配置 setenforce 0 sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config systemctl disable firewalld.service --now yum -y install chrony vim sed -i 's/^server/#server/g' /etc/chrony.conf sed -i '1s/^/server cn.pool.ntp.org iburst\n/' /etc/chrony.conf echo " 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.121 ws-k8s-master1 192.168.10.141 ceph-node1 192.168.10.142 ceph-node2 192.168.10.143 ceph-node3" > /etc/hosts
node安装ceph 每个节点安装 1 2 3 4 5 6 7 8 9 10 11 yum -y install epel-release yum -y install deltarpm yum-plugin-priorities yum-utils ntpdate python-setuptools python-pip gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel zip unzip ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssh openssl-devel nss_ldap openldap openldap-devel openldap-clients openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced python wget lsof iptraf strace lrzsz kernel-devel kernel-headers pam-devel tcl tk cmake ncurses-devel bison setuptool popt-devel net-snmp screen perl-devel pcre-devel net-snmp screen tcpdump rsync sysstat man iptables sudo libconfig git bind-utils tmux elinks numactl iftop bwm-ng net-tools expect snappy leveldb gdisk python-argparse gperftools-libs conntrack ipset jq libseccomp socat sshpass wget https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm --no-check-certificate rpm -ivh ceph-release-1-1.el7.noarch.rpm --force sed -i 's#download.ceph.com#mirrors.tuna.tsinghua.edu.cn/ceph#' /etc/yum.repos.d/ceph.repo yum install -y ceph-mon ceph-radosgw ceph-mds ceph-mgr ceph-osd ceph-common ceph
node1安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 hostnamectl set-hostname ceph-node1 && bash nmcli con modify ens18 ifname ens18 ipv4.method manual ipv4.addresses 192.168.10.141/24 \ ipv4.gateway 192.168.10.1 ipv4.dns 192.168.1.1 nmcli con up ens18 ssh-keygen ssh-copy-id ceph-node1 ssh-copy-id ceph-node2 ssh-copy-id ceph-node3 yum -y install ceph-deploy mkdir /ceph_clustercd /ceph_clusterceph-deploy new ceph-node1 ceph-node2 ceph-node3 ceph-deploy --overwrite-conf mon create-initial ls ceph.bootstrap-mds.keyring ceph.bootstrap-mgr.keyring ceph.bootstrap-osd.keyring ceph.bootstrap-rgw.keyring ceph.client.admin.keyring ceph-deploy admin ceph-node1 ceph-node2 ceph-node3 修改ceph.conf配置文件 cat /etc/ceph/ceph.conf[global] fsid = 30c9d277-1f46-4f97-b93e-b08327427c09 mon_initial_members = ceph-node1, ceph-node2, ceph-node3 mon_host = 192.168.10.141,192.168.10.142,192.168.10.143 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx
安装完成查看状态 #查看状态
services:
data:
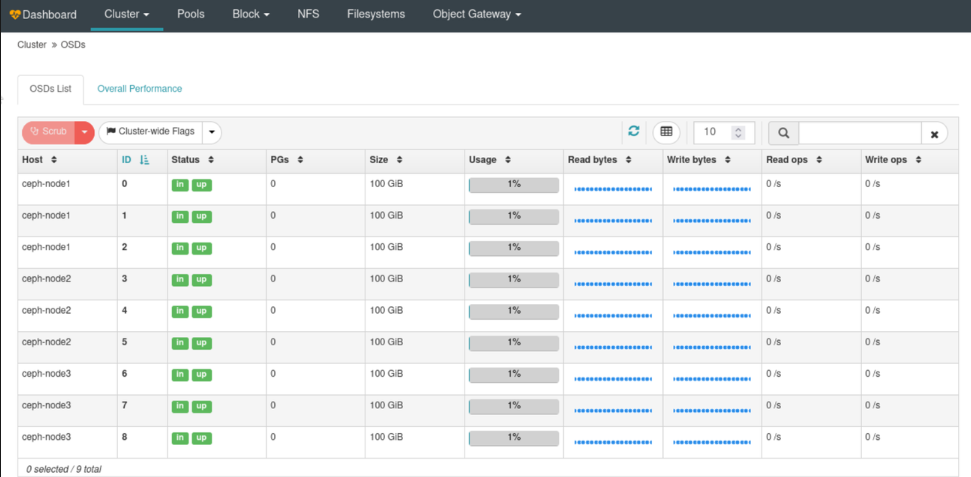
ceph OSD初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 49G 0 part ├─centos-root 253:0 0 45.1G 0 lvm / └─centos-swap 253:1 0 3.9G 0 lvm [SWAP] sdb 8:16 0 100G 0 disk sdc 8:32 0 100G 0 disk sdd 8:48 0 100G 0 disk sr0 11:0 1 4.5G 0 rom ceph-deploy osd create --data /dev/sdb ceph-node1 ceph-deploy osd create --data /dev/sdc ceph-node1 ceph-deploy osd create --data /dev/sdd ceph-node1 ceph-deploy osd create --data /dev/sdb ceph-node2 ceph-deploy osd create --data /dev/sdc ceph-node2 ceph-deploy osd create --data /dev/sdd ceph-node2 ceph-deploy osd create --data /dev/sdb ceph-node3 ceph-deploy osd create --data /dev/sdc ceph-node3 ceph-deploy osd create --data /dev/sdd ceph-node3 ceph -s cluster: id : 30c9d277-1f46-4f97-b93e-b08327427c09 health: HEALTH_WARN mons are allowing insecure global_id reclaim clock skew detected on mon.ceph-node3, mon.ceph-node1 services: mon: 3 daemons, quorum ceph-node2,ceph-node3,ceph-node1 (age 8m) mgr: ceph-node1(active, since 5m), standbys: ceph-node2, ceph-node3 osd: 9 osds: 9 up (since 7s), 9 in (since 7s) task status: data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 9.0 GiB used, 891 GiB / 900 GiB avail pgs: ceph-deploy osd list ceph-node1
ceph-Dashboard图形化仪表台 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 yum install -y ceph-mgr-dashboard ceph-deploy mgr create ceph-node1 ceph mgr module enable dashboard --force ceph config set mgr mgr/dashboard/server_addr 0.0.0.0 ceph config set mgr mgr/dashboard/server_port 8000 ceph mgr module disable dashboard ceph mgr module enable dashboard --force echo 'Admin@1234!' > dashboard_passwd.txtceph dashboard ac-user-create admin administrator -i dashboard_passwd.txt
ceph-rbd管理与卷的映射 基本管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ceph osd pool create pool_01 128 128 ceph osd pool application enable pool_01 rbd rados lspools ceph df ceph -s ceph osd pool get pool_01 size ceph osd pool set pool_01 size 2 ceph osd pool set pool_01 pgp_num 64 ceph tell mon.\* injectargs '--mon-allow-pool-delete=true' ceph tell mon.\* injectargs '--mon-allow-pool-delete=false' ceph osd pool delete pool_01 pool_01 --yes-i-really-really-mean-it
RBD管理与映射 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 rbd create pool_01/disk1 --size 10G rbd ls -p pool_01 rbd info pool_01/disk1 rbd image 'disk1' : size 10 GiB in 2560 objects order 22 (4 MiB objects) snapshot_count: 0 id : 38e4a2960771 block_name_prefix: rbd_data.38e4a2960771 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Mon Mar 18 10:11:24 2024 access_timestamp: Mon Mar 18 10:11:24 2024 modify_timestamp: Mon Mar 18 10:11:24 2024 [ 细颗粒度可以储存更多信息,但查询速度会变慢 rbd create --size 1G --order 21 pool_01/disk2 rbd create --size 1G --object-size 1M pool_01/disk3 rbd info pool_01/disk2 rbd image 'disk2' : size 1 GiB in 512 objects order 21 (2 MiB objects) snapshot_count: 0 id : 116d7fac892a block_name_prefix: rbd_data.116d7fac892a format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten op_features: flags: create_timestamp: Mon Mar 18 10:15:29 2024 access_timestamp: Mon Mar 18 10:15:29 2024 modify_timestamp: Mon Mar 18 10:15:29 2024 rbd rm pool_01/disk1 rbd rm pool_01/disk2 rbd rm pool_01/disk3
卷映射 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 49G 0 part ├─centos-root 253:0 0 45.1G 0 lvm / └─centos-swap 253:1 0 3.9G 0 lvm [SWAP] sdb 8:16 0 100G 0 disk └─ceph--a4c0f4de--3e33--4b4a--baad--d963051938dd-osd--block--d9c62f90--ad93--41ee--b53f--3695198c9935 253:2 0 100G 0 lvm sdc 8:32 0 100G 0 disk └─ceph--bcb89fc2--215e--41aa--b3d3--81c346933e63-osd--block--e989ef38--aef1--41c4--b427--f171cef6b88c 253:3 0 100G 0 lvm sdd 8:48 0 100G 0 disk └─ceph--2cf83101--f989--4a4b--bf13--257f399a9b24-osd--block--ce7869ba--31bf--4e39--8898--0b4fb32d5131 253:4 0 100G 0 lvm sr0 11:0 1 4.5G 0 rom rbd create pool_01/disk1 --size 10G rbd map pool_01/disk1 rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable pool_01/disk1 object-map fast-diff deep-flatten" . In some cases useful info is found in syslog - try "dmesg | tail" . rbd: map failed: (6) No such device or address rbd feature disable pool_01/disk1 object-map fast-diff deep-flatten rbd map pool_01/disk1 lsblk | grep rbd rbd0 252:0 0 10G 0 disk mkfs.ext4 /dev/rbd0 mkdir /ceph_volume01echo "/dev/rbd0 /ceph_volume01 ext4 defaults,_netdev 0 0" >> /etc/fstabmount -a df -Th | grep rbd/dev/rbd0 ext4 9.8G 37M 9.2G 1% /ceph_volume01
ceph-cephfs管理 注意点:(为什么k8s需要使用cephfs而不是rbd的方式进行挂载?
一个cephfs至少要求两个librados存储池,一个为data,一个为metadata 。当配置这两个存储池时,注意:
为metadata pool设置较高级别的副本级别,因为metadata的损坏可能导致整个文件系统不用
建议,metadata pool使用低延时存储,比如SSD,因为metadata会直接影响客户端的响应速度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 1.创建MDS元数据服务管理,MDS是ceph-fs的关键服务组件,用来存放元数据服务 ceph-deploy mds create ceph-node1 ceph-node2 ceph-node3 2.创建第一个存储池cephfs-data ceph osd pool create cephfs_data 128 3.创建metadata存储池 ceph osd pool create cephfs_metadata 128 4.基于创建的两个存储池来创建文件系统 ceph fs new ws-ceph-fs cephfs_metadata cephfs_data ceph fs ls name: ws-ceph-fs, metadata pool: cephfs_metadata, data pools: [cephfs_data]
ceph管理命令汇总与配置文件说明 配置文件ceph.conf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 mon clock drift allowed = 0.500 mon clock drift warn backoff = 10 [global] fsid = YOUR_CLUSTER_FSID mon_initial_members = MON_NODE1, MON_NODE2, MON_NODE3 mon_host = MON_NODE1, MON_NODE2, MON_NODE3 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx osd_journal_size = 1024 filestore_xattr_use_omap = true osd_pool_default_size = 3 osd_pool_default_min_size = 2 osd_pool_default_pg_num = 128 osd_pool_default_pgp_num = 128 [osd] osd_journal_size = 1024 [pool] pg_num_min = 8 pg_num_max = 4096 [mon] mon_osd_full_ratio = 0.95 mon_osd_nearfull_ratio = 0.85 [client] rbd_cache = true [log ] file = /var/log/ceph/ceph.log max_new = 10000 [debug] debug_default = 0 debug_mon = 20 debug_osd = 20
管理命令汇总 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 ceph -s ceph health ceph quorum_status ceph osd stat ceph df ceph osd pool create <pool_name> <pg_num> <pgp_num> <pool_type> ceph osd pool delete <pool_name> <pool_name> --yes-i-really-really-mean-it ceph osd pool get <pool_name> <key> ceph osd pool set <pool_name> <key> <value> ceph osd pool application enable <pool_name> <app_name> ceph osd pool application disable <pool_name> <app_name> ceph osd pool ls ceph osd tree ceph osd lspools ceph osd crush show-tunables ceph osd set <osd_id> <key> <value> ceph osd set-require-min-compat-client <release_name> ceph osd out <osd_id> ceph osd in <osd_id> ceph osd crush reweight <osd_id> <weight> ceph osd find <osd_id> ceph mon_status ceph mon stat ceph mon dump ceph mon getmap -o <file_name> ceph mon add <mon_name> <mon_ip> ceph mon remove <mon_name> ceph mds stat ceph mds dump ceph fs ls ceph fs status ceph fs set <fs_name> <key> <value> ceph fs set_max_mds <max_mds> ceph fs add_data_pool <fs_name> <pool_name> ceph fs rm_data_pool <fs_name> <pool_name> rados df rados lspools rados ls <pool_name> rados stat <pool_name> <object_name> rbd create <image_name> --size <size> --pool <pool_name> rbd ls <pool_name> rbd info <image_name> rbd resize <image_name> --很抱歉,由于文本格式的限制,无法在单个回答中提供所有的命令。请按照以下链接访问完整的 Ceph 管理命令合集: [Ceph 管理命令合集](https://docs.ceph.com/docs/master/rados/operations/administration/)
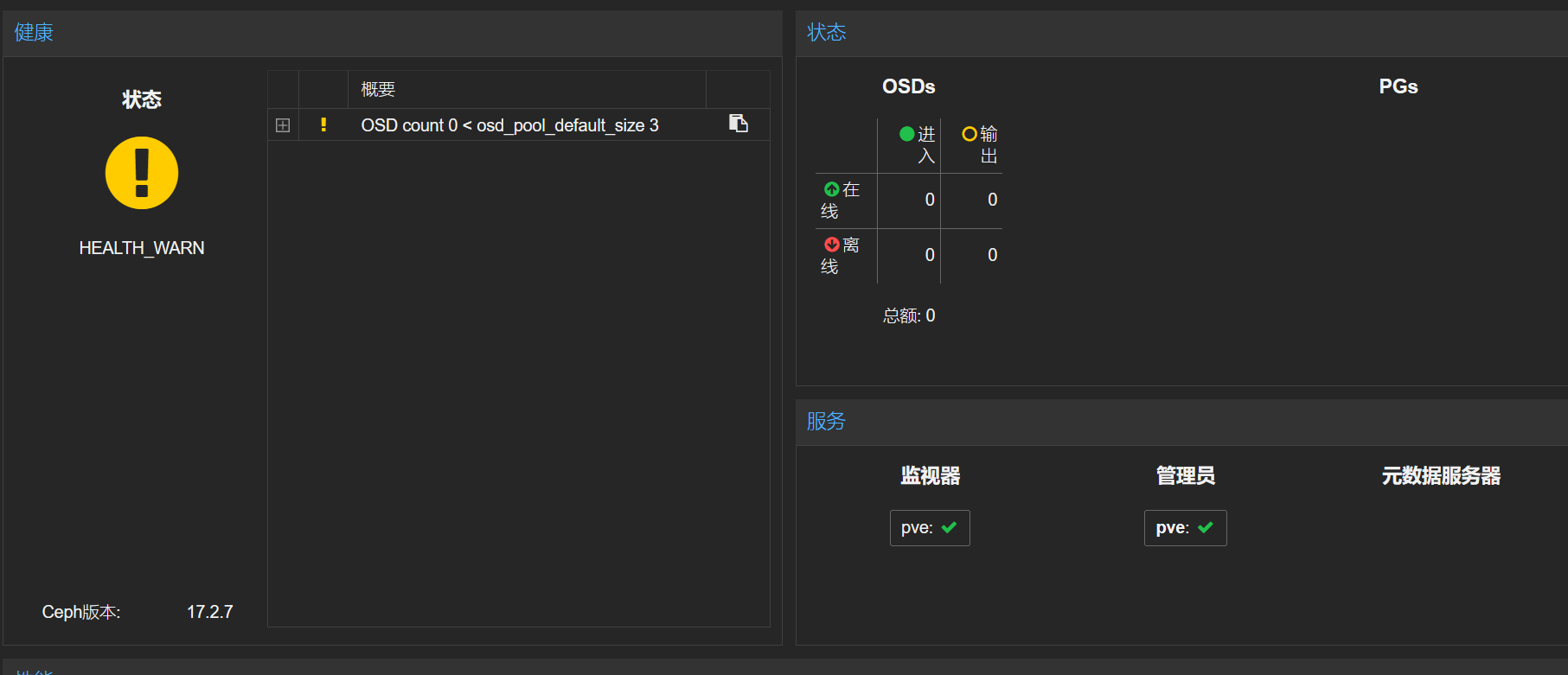
pve(debian)安装ceph 1 2 3 4 5 6 7 8 9 pveceph install --repository no-subscription pveceph init --network 192.168.10.0/24 pveceph createmon
此时再打开PVE界面能够看到ceph已激活