如果出现无法载图的情况,请检查与github的连通性
Anaconda开发环境介绍与搭建 Anaconda是一个软件集合,自带了很多的模块的二进制文件(可以直接本地构建模块),并提供了conda和pip两个包管理工具。能够提供python解释器、模块与虚拟环境的管理
模块 —— 实现具体功能的工具包 比如想实现下载、上传功能,存储功能,可以寻找现成的网络的、数据库的模块可以来调用
虚拟环境 —— 给开发环境做用途上的区分 通过划分多个开发环境,为不同的环境设置不同版本的解释器和模块,比如区分python2与3的环境
pip和conda包管理工具的对比: (1)软件仓库的区别
(2)模块内容
(3)支持的语言
(4)多环境
(5)依赖的检查
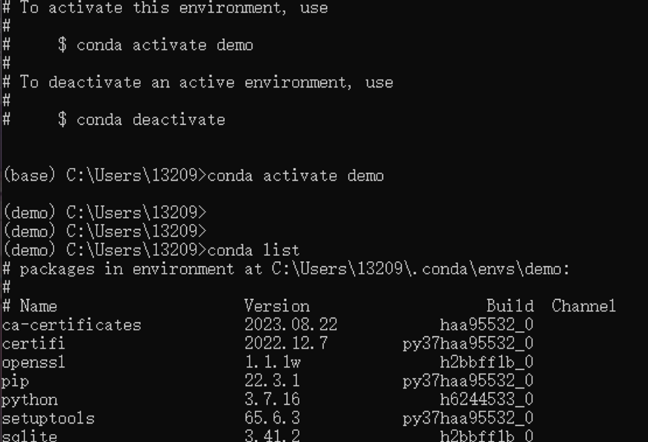
anaconda的conda与pip命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 1 、一般操作conda -version conda update conda conda update pip conda update anaconda conda env list 在linux和macos中 source activate xx source deactivate 在windows中 activate xx deactivate 2 、创建虚拟环境conda create --name/-n 新环境名 conda create -n 新环境名 -c 老环境名 conda remove -n 环境名 --all 3 、操作模块conda/pip install -n 环境名 模块1 ,模块2 ,模块3 (base)conda install 模块1 ,模块2 ,模块3 conda list -n 环境名 conda uninstall 模块名 conda install -n 环境名 python=3.7 conda create -n demo python=3.7 requests
windows安装anaconda与pycharm 在清华大学开源镜像站-anaconda-miniconda找到安装包进行下载最新版本
安装过程中选择添加到环境变量,以及作为默认解释器,反正全勾上了
直接默认安装pycharm
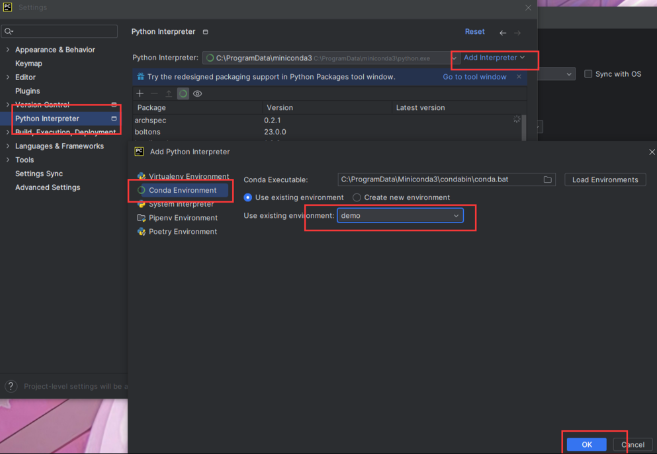
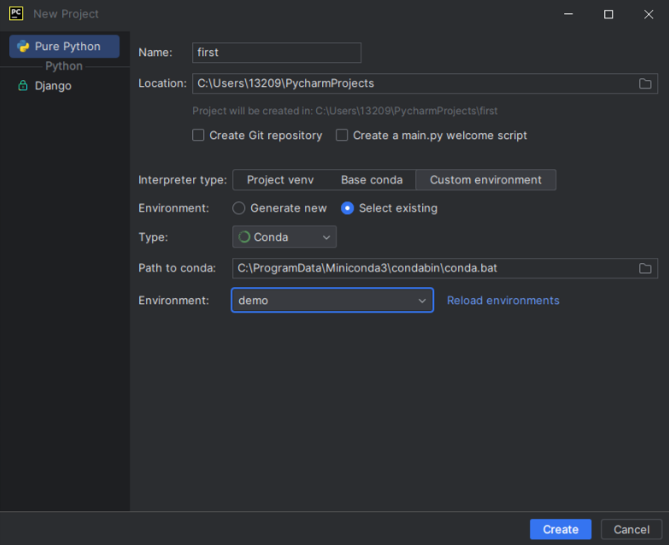
创建新项目,选择conda环境——demo环境——选择创建
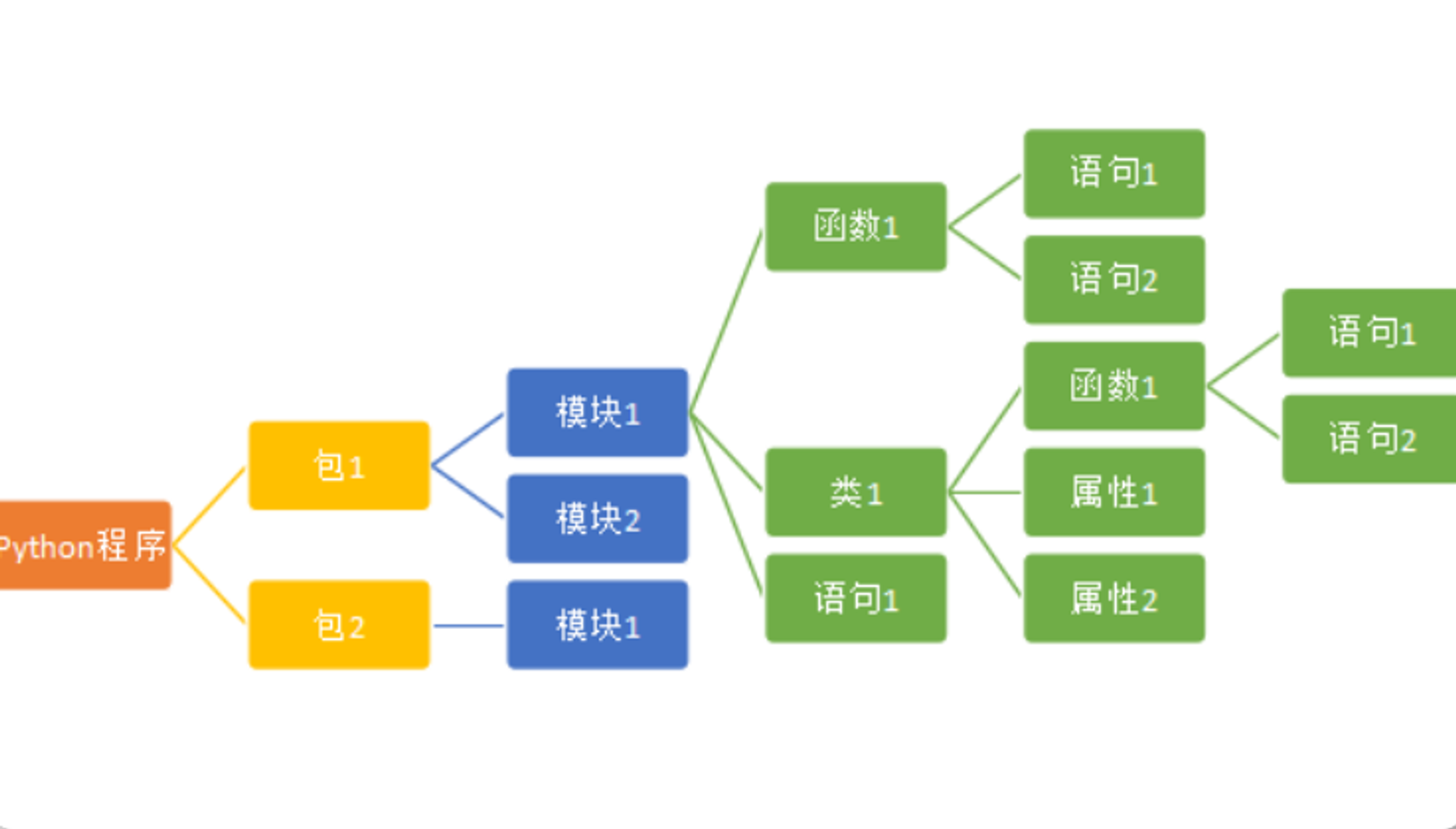
标识符与数据类型 python程序的构成 Python程序是由模块组成的。每个模块都对应一个py源文件
Python是一种强制使用缩进的语言,1个tab制表符或4个空格代表一个缩进
书写中可以使用行连接符\
Python官网建议使用PEP-8代码风格https://www.python.org/dev/peps/pep-0008/
注释 注释方法:
解释器位置特殊注释:-coding:utf8- -
标识符定义规则 标识符规则:用于变量、函数、类、模块等的名称
驼峰命名法:
Python标识符命名规则 开发中,我们通常约定俗称遵守如下规则
关键字和内置函数 都是python开发者定义封装好嗷的,具有特殊意义
变量 赋值:
其本质为:
变量删除与垃圾回收机制 通过del可以删除变量,del a 代表将栈内存中的a删除
链式赋值 用于同一个对象赋予多个变量
x=y=500
解包赋值 a,b,c = 10,20,30
a,b = b,a #互换
数据类型 Python是动态类型的语言,不需要显示声明类型。
整形int
1 2 3 4 5 var=100_0000 var=1.5e5
整型int 在Python2中,int是32位,long类型64位
1 2 3 4 5 6 7 8 a = 0b10101010 b = 0o123 c = 0x8e d = int("123") e = int(10.5) f = 10.0 + 8 type(f) print(a,b,c,d)
浮点型float 用科学计数法表示
1 2 3 4 5 6 7 8 9 a = 3.14 b = 352e-3 c = 413.02 d = round(c) float()#类型转换 y += x*2 y *= x + 2
布尔值 在Python中,将true和false定义成了关键字。true其实就是1,false是0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 a = true b = 5 print (a+b)if ("" ): print ("true" ) else print ("false" ) bool 的空字符串——> falsebool 的空列表——> falsebool 的None ——> falsebool 的0 ——> false只有bool ("False" ),结果是true
运算符 基本运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 //表示整除,不会产生小数 **表示乘方 var=64 ** (1/2) %表示取余 x+=y x-=y x*=y x/=y x//=y x%=y x**=y divmod0()方法-同时得到商和余数
运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 print (a is b) not is != == 其本质为使用__eq__方法 and or not in () 乘方 乘除 加减 比较运算符 in not and or var="ws is \"ws\"" a="asd" b="asdqwe" print (a in b)
位运算符
1 2 3 4 5 6 7 8 9 10 位运算 a = 0b000110 b = 0b011010 bin ()转换为二进制print (bin (a&b)) print (bin (a|b)) print (bin (a^b)) print (bin (a~)) print (bin ())s
整数缓存问题 命令行模式下,python仅对比较小的整数进行对象缓存,范围为-5到256
文件模式下,所有数字都会被缓存
-5到256依然底层用数组实现,除此之外的数缓存到链表中
1 2 3 4 5 6 7 8 a=5 b=5 print (a is b)a=267 b=267 print (a is b)
字符串 在python中,单字符也是字符串类型
python中的字符串是不可变的
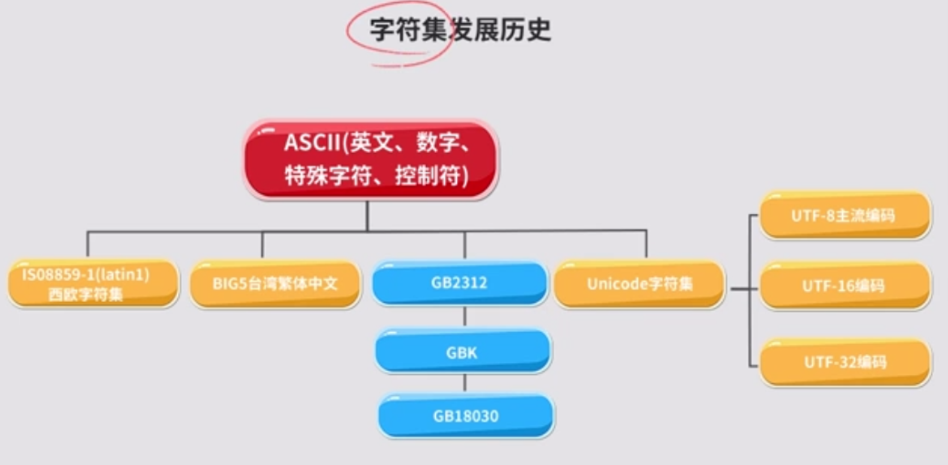
编码 python3直接支持字符集Unicode,可以表示所有字符
python3字符默认为16位的Unicode编码,ASCII码是Unicode的子集
使用内置函数ord()可以把字符转换成对应的Unicode码;
1 2 3 4 print (ord ("王" ))print (ord ("盛" ))30427
字符串创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var=""" 123455 '12345' """ input ('提示信息' ) print ("123" ,end='' )print ("123" )
字符串的拼接 1 2 3 4 5 var="1" print (var * 20 ) print (var1 + var2) print ("123" +"12345" )
转义字符 实现某些难以用字符表示的效果。比如:换行等。常见的转义字符有这些:
转义字符
描述
(在行尾时)
续行符
\
反斜杠符号
‘
单引号
“
双引号
\b
退格(Backspace)
\n
换行
\t
横向制表符
\r
回车
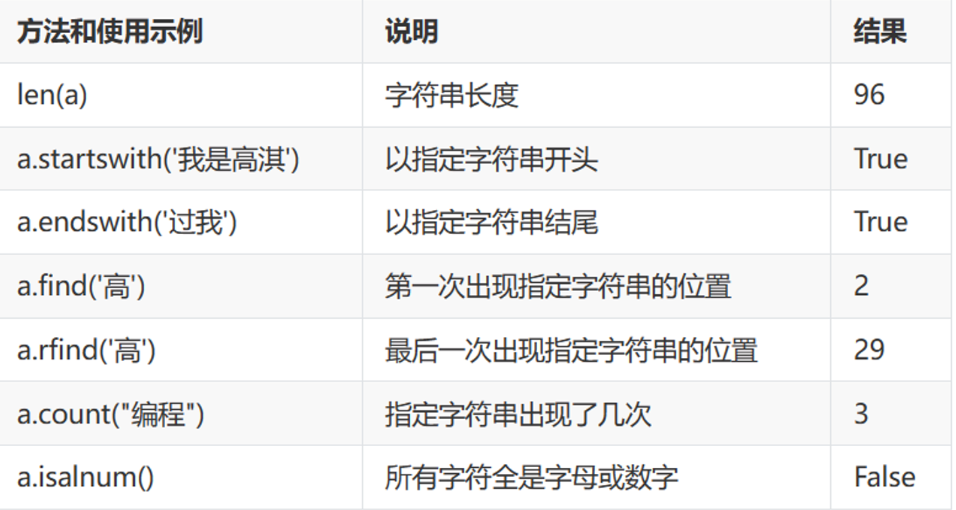
字符串操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 字符串是不能变的,所以只能创建一个新对象,将变量指向新的对象 print (var.replace('老字符' ,'新字符' ,'替换次数,-1为全部替换' )) a = '123' print (a.replace('1' ,'王' ))var="qwe poi" print (var.startswith('ab' )) print (var.endswith('e' )) var="QwErT y sTj" print (var.capitalize()) print (var.title()) print (var.lower()) print (var.upper()) print (var.strip()) print (var.lstrip()) print (var.rstrip()) print (var.strip('y' )) var.startswith('xx' ) var.endswith('xx' ) 在字符串中每个字符都有一个索引,第一位索引是0 索引超出也不会报错,与序列的切片一致 var="qwertyu" print (var[2 ]) print (var[0 :7 ]) print (var[-4 :-1 ]) print (var[-4 :]) print (var[-4 :-0 :2 ]) print (var[::-1 ]) var="qwe poi" print (var.find('poi' )) print (var.index('poi' )) var='qw er ty ui' var.split() 默认参数为 print (var.split()) print (var.split('r' ))print ('' .join(var.split()))print ('*' .join(var.split()))现在有两种方法可以输出同一字符串到字符串中 1. 使用+=的方法a =+ "123" 2. 将"123" 添加到一个列表中然后用join将列表合并成str 1 方法的效率需要重复生成字符串,效率很低。要用2 var="王盛" print (var.center(10 ))print (var.center(20 ,'*' ))print (var.ljust(10 )) print (var.rjust(10 )) isalnum() 是否为字母或数字 isalpha() 是否只有字母或汉字 isdigit() 是否只有数字 isspace() 是否为空白符 isupper() 是否为大写字母 islower() 是否为小写字母
可变字符串 io.StringIO() 是一个在内存中操作字符串数据的工具,它允许你像文件一样读写字符串,但它是可变
1 2 3 4 5 6 7 8 9 10 import ioa = 'adwqewq' aio = io.StringIO(a) print (aio) print (aio.getvalue())aio.seek(3 ) aio.write("***" ) print (aio.getvalue())
字符串驻留机制 双引号引起来的字符串,如果相同则只保存一份,被认为是同一个对象,ID也相同
1 2 3 4 5 6 7 8 9 10 11 12 13 a = "名字:{0},年龄:{1}" b = a.format ("ws" ,'25' ) c = a.format ("xhy" ,'24' ) print (b)print (c)d = "名字 {name},年龄 {age}" print (d.format (name='ws' , age=24 ))
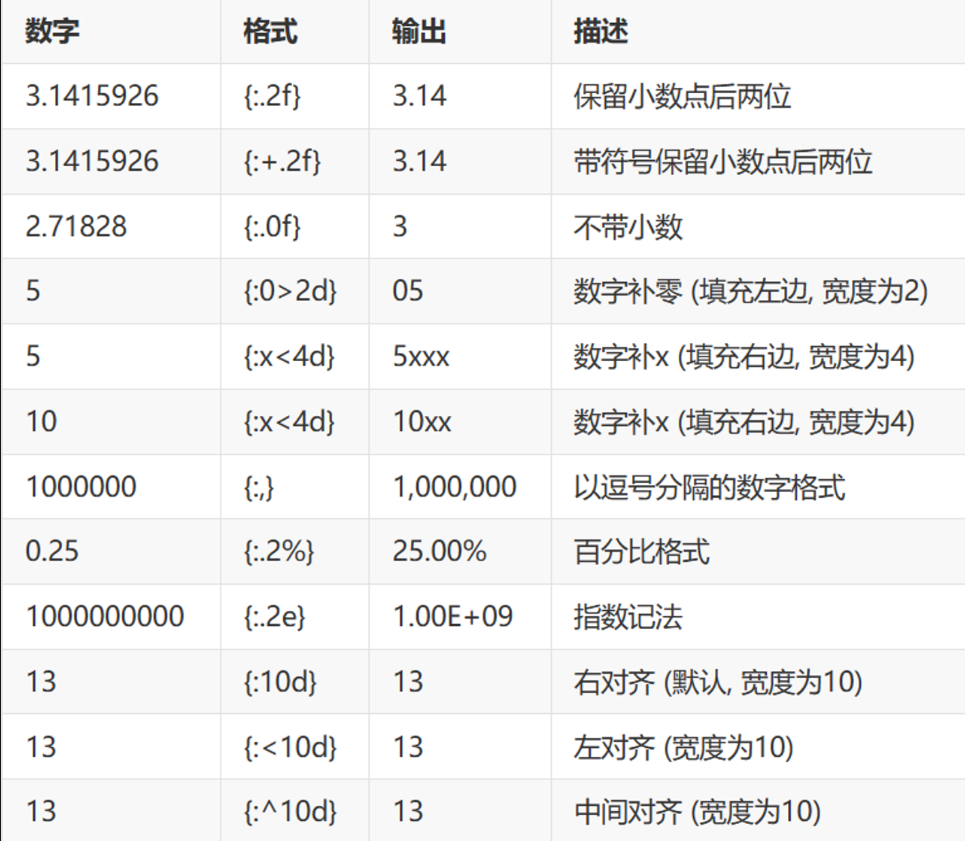
数字格式化 1 2 3 a = "我是{0},工资{1:.2f}" print (a.format ('ws' ,0.05 ))
类型转换
类型转换
int(x [,base])
将x转换为一个整数
long(x [,base] )
将x转换为一个长整数
float(x)
将x转换到一个浮点数
complex(real[,imag])
创建一个复数
str(x)
将对象 x 转换为字符串
repr(x)
将对象 x 转换为表达式字符串
eval(str)
用来计算在字符串中的有效Python表达式,并返回一个对象
Complex(A)
将参数转换为复数型
tuple(s)
将序列 s 转换为一个元组
list(s)
将序列 s 转换为一个列表
set(s)
转换为可变集合
dict(d)
创建一个字典。d 必须是一个序列 (key,value)元组
frozenset(s)
转换为不可变集合
chr(x)
将一个整数转换为一个字符
unichr(x)
将一个整数转换为Unicode字符
ord(x)
将一个字符转换为它的整数值
hex(x)
将一个整数转换为一个十六进制字符串
oct(x)
将一个整数转换为一个八进制字符串
序列 常见的序列有:列表、字典、元组、集合、双端队列、区间
列表 列表是一种常用的数据结构,可以容纳各种类型的数据
列表是内置可变序列,包含多个元素的有序连续内存空间,并且可以根据需要随时增大和缩小
列表的创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 list1=[] list2=list () print (list (range (10 )))推导式生成列表 a = [x*2 for x in range (3 )] range (3 )=[0 ,1 ,2 ]a = [0 ,2 ,4 ] b = [x*2 for x in range (50 ) if x%9 ==0 ] range (2 ,20 ,4 ) 需要使用list ()使其变成列表 list1=[1 ,'2354' ,False ,[1 ,2 ]] print (type (list1))tuple1=(1 ,2 ,3 ) print (type (tuple1)) tuple1= list (tuple1) print (type (tuple1))
列表操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 list1=[1 ,2 ,3 ,4 ,5 ,6 ] list2=[1 ,2 ,3 ] print (list1 + list2)list1.extend(list2) print (list1)print (list2 * 2 )list1=[1 ,2 ,3 ,4 ] list1.append('12345sq' ) print (list1)list1.append([1 ,2 ]) print (list1)list1=[1 ,2 ,3 ,4 ] list1.insert(0 ,'wqe' ) print (list1)插入和删除都需要改变元素的位置,会影响性能 list1=[1 ,2 ,3 ,4 ] list1.remove(4 ) remove不存在会报错 print (list1)list1.pop() var=list1.pop() print (var)del list [0 ] list1=[1 ,2 ,3 ,4 ,5 ] list1[0 ]='ws' print (list1)list1=[1 ,2 ,3 ,4 ,5 ,['ws' ,'qwe' ,['ert' ,'uty' ]]] print (list1[5 ][2 ][1 ])list1=[1 ,2 ,3 ,4 ,5 ] list1.reverse() print (list1)list1=['qwe' ,'asdc' ,'szcqqq' ,'aaaaaaa' ,'a' ] list1.sort(key=len ,reverse=False ) print (list1)返回一个迭代器对象,并且只能使用一次 a = [10 ,50 ,30 ,60 b = reversed (a) c = list (b) print (c)import randomlist1=[1 ,2 ,3 ,4 ,5 ,6 ,1 ] random.shuffle(list1) print (list1)
列表遍历len max min 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 list1=[1 ,2 ,3 ,4 ,5 ] list2=['10' ,'20' ,'30' ,'40' ,'50' ] str1='ABCDE edcba' print (len (list1)) print (len (list2)) print (len (str1)) print (max (list1)) print (max (list2)) print (max (str1)) 只针对数值型列表 print (sum (a))
统计次数、指定元素:count、index方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 list1=[1 ,2 ,3 ,4 ,5 ,6 ,1 ] print (list1.count(1 ))list1=[1 ,2 ,3 ,4 ,5 ,6 ,1 ] print (list1.index(4 )) list1=[1 ,2 ,3 ,[4 ,5 ],6 ,1 ] print (list1.index(5 )) list1=[1 ,2 ,3 ,['4' ,5 ],6 ,1 ] print (list1.index('4' )) list1=[1 ,2 ,3 ,['4' ,5 ],6 ,1 ] print (list1[3 ].index('4' ))
列表切片 与字符串的切片几乎相同
1 2 3 4 5 6 7 8 9 list1=[1 ,2 ,3 ,4 ,5 ,6 ] print (list1[3 ]) print (list1[0 :4 ]) print (list1[1 :]) print (list1[:4 ]) print (list1[1 :-1 ]) print (list1[1 :5 :2 ])
字典 通过键值对key=value的形式保存元素的一种数据结构
字典的创建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } print (type (dict1)) dict1=dict ([['qwe' ,'ewq' ],['asd' ,'dsa' ]]) dict2=dict (name='ws' , age='25' , job=None ) print (dict1)print (dict2)k=['name' ,'age' ,'居住地' ] v=['ws' ,'25' ,'sx' ] d = dict (zip (k,v)) print (d)a=dict .fromkeys(['name' , 'age' , 'job' ]) print (a)
字典的操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } print (dict1['ws' ])print (dict1['NA' ])print (dict1.get('NA' ))dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } dict1['ads' ]='qcvx' print (dict1)dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } dict1.setdefault('ads' ,'wqw' ) print (dict1)dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } del dict1['ws' ]print (dict1)dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } var=dict1.pop('ws' ) print (var)print (dict1)dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } dict1['ws' ]='ws' print (dict1)dict1.update({'ws' :'wsc' }) print (dict1)dict1={'ws' :123 ,'qwe' :'weq' ,'王' :'sheng' } print (dict1.keys())print (dict1.values())print (dict1.items())
元组 一种不可变的数据结构,一旦创建不能添加、删除与修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 tuple1=(1 ,'2' ,True ,[2 ,4 ],(1 ,2 )) print (type (tuple1)) list1=[1 ,2 ,3 ] tuple1=tuple (list1) print (tuple1)tuple1=(1 ,'2' ,True ,[2 ,4 ],(1 ,2 )) var1=2 tuple1=(var1,'2' ,True ,[2 ,4 ],(1 ,2 )) print (tuple1)
封包与解包 封包:将多个值赋值给一个变量
1 2 3 4 5 6 7 8 9 10 11 tuple1=(1 ,2 ,3 ,4 ) var1,var2,var3,var4=tuple1 print (var1,var2,var3,var4)tuple1=(1 ,2 ,3 ,4 ) *var1,var2,var3=tuple1 print (var1,var2,var3)
集合 分为可变集合set和不可变集合fornzset
特点:不支持索引,元素随机排列,只能包含常量,不能重复,有重复自动删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 set1={1 ,2 ,3 ,5 ,6 ,7 ,8 ,7 ,8 ,True ,(1 ,3 )} print (type (set1)) print (set1)set1={1 , 2 , 3 , (1 , 3 ), 5 , 6 , 7 , 8 } set1.add('ws' ) print (set1)set1.remove('ws' ) print (set1)set1.remove('ws' ) print (set1)set1.discard('ws' ) print (set1)list1=[1 ,2 ,3 ,4 ] list2=[2 ,3 ,4 ,5 ,6 ] list3=list (set (list1 + list2)) print (list3)
集合的关系测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 set1={1 ,2 ,'qwe' } set2={2 ,3 ,'erq' } set3={1 ,5 ,4 ,'qwe' } print (set1.issubset(set2)) print (set1.issuperset(set2)) print (set1.difference(set3)) set1-set3 print (set1) set1.difference_update(set3) print (set1)set1=set1.intersection(set3) set1 & set3 print (set1)set1.intersection_update(set2) print (set1)set1=set1.union(set2) print (set1)set1.update(set2) print (set1)
不可变集合 和元组差不多,所以不支持自动生效的关系测试的方法,例如只支持关系判断issubclass,集合相减difference,集合相交intersection,集合并集union
元组是有序的,但不可变集合是无序的
1 2 3 4 fest1=frozenset ([1 ,2 ,3 ,4 ]) print (type (fest1))
流程控制方法 流程控制有三种方法:分支、循环、跳出
流程的控制通过布尔值来实现,分支和循环都需要对一定的条件进行判断,根据判断结果(布尔值)决定下一步要做什么
布尔值通过比较运算符、逻辑运算符来进行判断是True还是False
不需要判断直接得到True——数字1,非空数据类型与结构,如非空list,非空string,非空set等
不需要判断直接得到False——数字0,空数据类型与结构
博主以前学过51和c,这块就轻松很多,快速带过
分支 分支是根据条件,让有些代码可以被执行或不被执行
分支关键字有:if、else、elif、pass
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 var = 123 if var == '111' : print ('123123123' ) print ('over' ) var = 123 if var == '111' : print ('123123123' ) else : print ('ws' ) print ('over' ) var = 68 if var >= 80 : print ('优秀' ) elif var >= 70 : print ('良好' ) elif var >= 60 : print ('及格' ) else : print ('不及格' ) print ('over' )dict1 = {'ws' :'1111' ,'xhy' :'2222' } name = input ('username:' ) if name in dict1.keys(): pwd = input ('password:' ) if pwd == dict1[name]: print ('success' ) else : print ('error' ) else : print ('no such username' ) dict1 = {'ws' :'1111' ,'xhy' :'2222' } name = input ('username:' ) if name in dict1.keys(): pwd = input ('password:' ) if pwd == dict1[name]: pass else : print ('error' ) else : print ('no such username' ) var = int (input ('soure:' )) print ('good' if var >= 60 else 'bad' ) 等同于: if var >= 60 : print ('good' ) else : print ('bad' )
循环 让某些代码重复执行
关键字包括for、while
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 list1 = [] i = 1 while i <= 10 : list1.append(i) i += 1 print (list1)list1=[1 ,2 ,3 ,4 ,5 ] for i in list1: print (f'{i} ' ) i += 1 str ='wsxhy' for i in str : print (f'{i} ' ) var=[(1 ,2 ,3 ),(4 ,5 ,6 ),(7 ,8 ,9 ),(10 ,11 ,12 )] for v1,v2,v3 in var: print (f'{v1} ,{v2} ,{v3} ' ) var=[(1 ,2 ,3 ),(4 ,5 ,6 ),(7 ,8 ,9 ),(10 ,11 ,12 )] for i in var: print (i) dict1={'ws' :1 ,'xhy' :'qwe' ,'esq' :'12w' } for i in dict1.items(): print (f'{i} ' ) a = 0 while a <= 10 : for i in range (3 ): print (i) a += 1 list1=[i for i in range (1 ,21 )] print (list1)等同于 list1 = [] i = 1 while i <= 20 : list1.append(i) i += 1 print (list1)list1=[i*2 for i in range (1 ,21 )] list1=[i for i in range (1 ,21 ) if i % 2 == 0 ]
跳出 跳出循环的方法,有break与continue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 i =1 list1 = [] while i <= 20 : if i == 5 : break list1.append(i) i += 1 print (list1)list1 = [] for i in range (1 ,8 ): if i == 5 : continue list1.append(i) print (list1)for i in range (1 ,10 ): pass else : pass user_list={'ws' :'1' ,'xhy' :'2' ,'qwe' :3 } name =input ('name:' ) for i in user_list: if i == name: break else : print ('error' ) name = input ('name:' ) find='' for i in user_list: if i == name: find = True break find = False if find is False : print ('error' ) while True : pass else : pass
练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 users=[{'ws' :'ws111' },{'xhy' :'xhy111' },{'qwe' :'qwe111' }] name=input ('username:' ) for v1 in users: if name in v1.keys(): password=input ('password:' ) if password in v1.values(): print ('login successful' ) break else : print ('password incorrect' ) break else : print ('no such user' )
通过循环来遍历可迭代对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 user1 = {'name' : '王盛' ,'age' :'25' ,'salary' :'5000' ,'address' :'sx' } user2 = {'name' : 'xhy' ,'age' :'25' ,'salary' :'5000' ,'address' :'yk' } user3 = {'name' : 'zhz' ,'age' :'25' ,'salary' :'5000' ,'address' :'hz' } tb = [user1,user2,user3] for x in user1: print (x) for x in user1.values(): print (x) for x in user1.items(): print (x) name age salary address 王盛 25 5000 sx ('name' , '王盛' ) ('age' , '25' ) ('salary' , '5000' ) ('address' , 'sx' )
嵌套循环练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 输出乘法口诀表: for n in range(1,10): for m in range(1,n+1): print ("{0}*{1}={2}" .format(n,m,n*m),end='\t' ) print () 1*1=1 2*1=2 2*2=4 3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 4*3=12 4*4=16 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81 输出工资大于6000的人的信息: user1 = {'name' : '王盛' ,'age' :'25' ,'salary' :4000,'address' :'sx' } user2 = {'name' : 'xhy' ,'age' :'25' ,'salary' :5000,'address' :'yk' } user3 = {'name' : 'zhz' ,'age' :'25' ,'salary' :6000,'address' :'hz' } tb = [user1,user2,user3] for x in tb: if x.get('salary' ) > 5000: print (x)
循环中的优化
尽量减少循环中不必要的计算
尽量减少内层循环的计算
尽量使用局部变量,查询较快
连接多字符串时,尽量使用join
函数 函数是将代码封装起来,实现代码复用的目的
函数的分类:
函数的命名规则——同变量命名规则:
LEGB规则——查找顺序 如果某个name映射在局部local命名空间中没有找到,接下来就会在闭包作用域enclosed进行搜索,如果闭包作用域也没有找到,Python就会到全局global命名空间中进行查找,最后会在内建built-in命名空间搜索 (如果一个名称在所有命名空间中都没有找到,就会产生一个NameError)
Local 指的就是函数或者类的方法内部
Enclosed 指的是嵌套函数(一个函数包裹另一个函数,闭包)
Global 指的是模块中的全局变量
Built in 指的是Python为自己保留的特殊名称
函数的格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def 函数名 ([参数列表] ): """文档字符串(注释)""" 注释可以通过help (函数名)来获取 函数体和语句 例: def add (a,b,c ) """相加""" print ("{0}、{1}、{2}的和是{3}" .format (a,b,c,(a+b+c))) add(10 ,20 ,30 ) 返回值: 1. 没有定义返回值,返回值为None 2. 定义了返回值,返回指定的值,可以用来赋值给另外的变量3. 返回值返回后,类型是一致的python执行def 时,会创建一个函数对象,绑定到函数变量名上 函数在定义时,只需要定义形参,且不需要声明类型,不需要制定返回值类型 函数的内存分析: def 定义函数后,系统就创建了相应的函数对象,并通过print_star这个变量进行引用print_star这个变量存放在栈stack中,他在物理内存中的地址是这个函数对象的id 在执行了c=print_star后,c也存放在了stack中,**c和print_star是同一个函数对象**
函数变量 分为全局变量和局部变量
在函数里和不在函数里的区分,很好区分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def f1 (): global a print (a) nolocal a 每次调用方法,都会产生一个栈帧 在栈帧中,调用a的值 a = 100 def f1 (a,b,c ): print (a,b,c) print (locals ()) print ("#" *20 ) print (globals ()) def f2 (a,b,c ): f1(2 ,3 ,4 )
函数参数的传递 本质上就是:从实参到形参的赋值操作。Python中“一切皆对象”,所有的赋值操作都是“引用的赋值”。所以,Python中参数的传递都是“引用传递”,不是“值传递”。
对“可变对象”进行“写操作”,直接作用于原对象本身。
1 2 3 4 5 6 7 8 9 10 11 12 b = [10 ,20 ] def f2 (m ): print ("m:" ,id (m)) m.append(30 ) f2(b) print ("b:" ,id (b))print (b)ID一样,说明他们两个是同一个对象,所以是“只引用”,不“新创建”
2 .对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用。在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 a = 100 def f1 (n ): print ("n:" ,id (n)) n = n+200 print ("n:" ,id (n)) print (n) f1(a) print ("a:" ,id (a))在赋值之前还是相同的对象,但赋值之后就生成了新的对象,同时也不影响原本的a的值 如果拷贝的是不可变对象,但不可变对象内的子对象是可变的(比如元组不可变,但元组内有一个列表) 在元组中,记录的是列表的地址,所以调用进行修改时,会直接用列表的地址进行修改
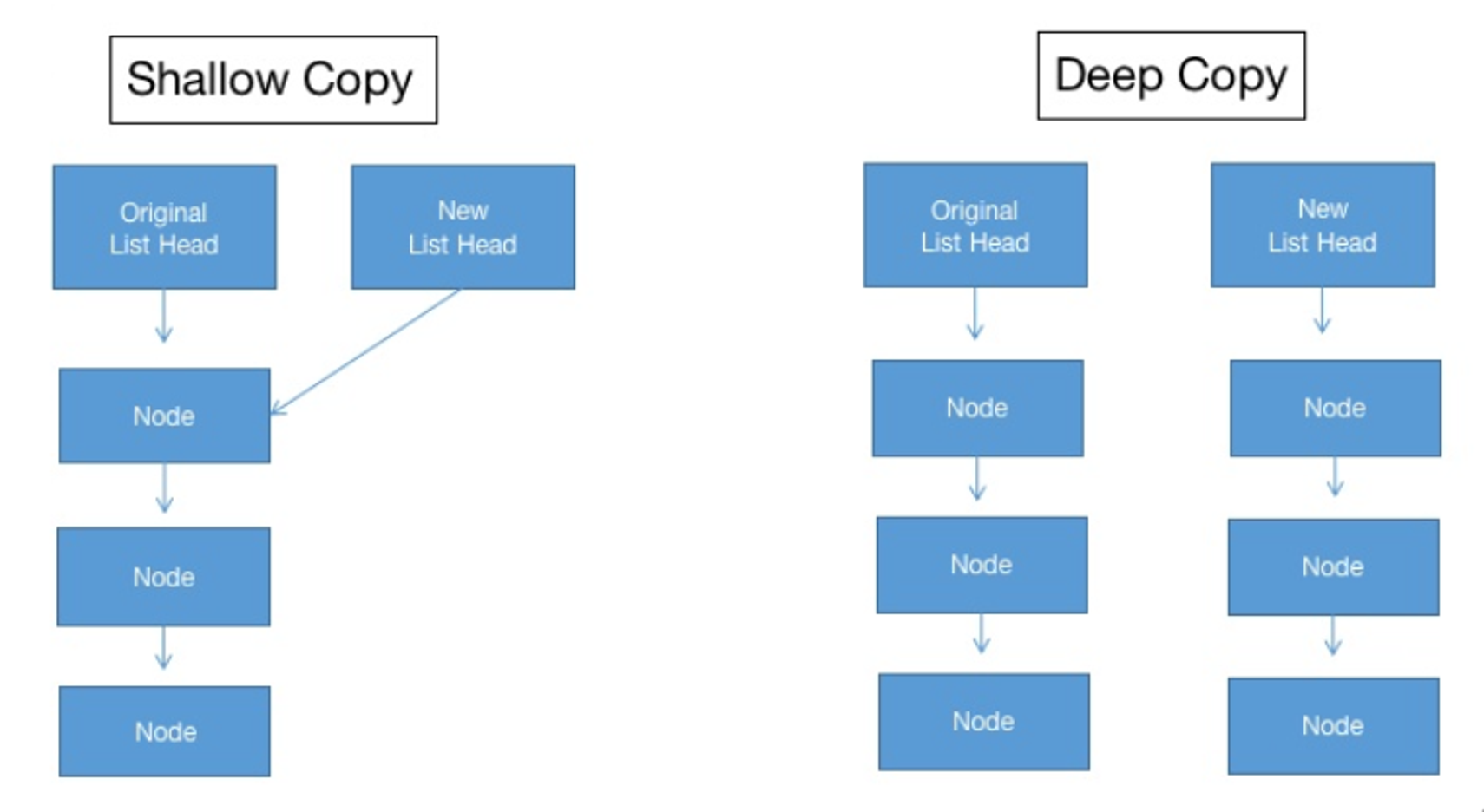
浅拷贝和深拷贝
内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝: 拷贝对象,但不拷贝子对象的内容,只是拷贝子对象的引用。深拷贝: 拷贝对象,并且会连子对象的内存也全部(递归)拷贝一份,对子对象的修改不会影响源对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 浅拷贝 import copydef testCopy (): '''测试浅拷贝''' a = [10 , 20 , [5 , 6 ]] b = copy.copy(a) print ("a" , a) print ("b" , b) b.append(30 ) b[2 ].append(7 ) print ("浅拷贝......" ) print ("a" , a) print ("b" , b) a [10 , 20 , [5 , 6 ]] b [10 , 20 , [5 , 6 ]] 浅拷贝...... a [10 , 20 , [5 , 6 , 7 ]] b [10 , 20 , [5 , 6 , 7 ], 30 ] 此时b和a是独立的,但是b引用了a的子集 所以修改b本身时a不会变化 但是b引用的a的子集,他们指向的是同一个对象
一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 深拷贝 def testDeepCopy (): '''测试深拷贝''' a = [10 , 20 , [5 , 6 ]] b = copy.deepcopy(a) print ("a" , a) print ("b" , b) b.append(30 ) b[2 ].append(7 ) print ("深拷贝......" ) print ("a" , a) print ("b" , b) 深拷贝,子集也不共享
另一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import copyclass Mobilephone : def __init__ (self,cpu ): self.cpu = cpu class CPU : pass c = CPU() m = Mobilephone(c) print ("浅拷贝" )m2 = copy.copy(m) print ("m:" ,id (m))print ("m:" ,id (m2))print ("m中的CPU" ,id (m.cpu))print ("m中的CPU" ,id (m2.cpu))print ("深拷贝" )m3 = copy.deepcopy(m) print ("m:" ,id (m))print ("m:" ,id (m3))print ("m中的CPU" ,id (m.cpu))print ("m中的CPU" ,id (m3.cpu))
main函数与一些常识 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 list1=['wadsad' , 'qweqwe' ] def show (list_name ): for i in list_name: print (f'{list_name.index(i) + 1 } .{i} ' ) if __name__ == '__main__' : show(list1) help (print ) def show (list_name ): """ :param list_name: :return: """ for i in list_name: print (f'{list_name.index(i) + 1 } .{i} ' ) print (show.__doc__)def fun (): v1 = 1 v2 = 2 v3 = 3 return v1,v2,v3 if __name__ == '__main__' : var1,*var2 = fun() print (var2)
传参 参数的类型:
位置参数——调用时实参按顺序传送,必须一对一匹配
默认值参数——在定义时就放在函数中的参数,且必须在位置参数后面
命名参数——在调用时指定,通过名字来区分
可变参数:——要放到所有参数最后
param(一个星号),将多个参数收集到一个“元组”对象中。*param(两个星号),将多个参数收集到一个“字典”对象中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def fun (var ): print (f'{var} ' ) if __name__ == '__main__' : var1 = input ('press:' ) fun(var1) def fun (var1,var2 ): v1 = var1 * 2 v2 = var2 + 10 return v1,v2 if __name__ == '__main__' : fun(123 ,456 ) def fun (var1,var2,var3 ): print (var1,var2,var3) if __name__ == '__main__' : fun(var2=456 ,var1=123 ,var3=789 ) fun(123 ,456 ,var3=789 ) def fun (var3,var2,var1=3 ): print (var1,var2,var3) if __name__ == '__main__' : fun(1 , 2 , 4 ) fun(1 , 3 ) def fun (v1,v2,*args,v3 ): print (args) if __name__ == '__main__' : fun(123 ,12345 ,'qwe' ,True ,v3=123 ) def fun (v1,**kwargs ): print (kwargs) if __name__ == '__main__' : fun(True ,name='ws' ,age=24 ,passwd='ws111' ) def fun (var1,*var2 ): print (var1,var2) if __name__ == '__main__' : list1 = ['ws' ,'xhy' ,111 ,222 ] fun(*list1) def fun (var1,var2,**var3 ): print (var1,var2,var3) if __name__ == '__main__' : dict1 = {'var1' :'ws111' ,'var2' :True ,'v1' :'v1' ,'v2' :'v2' } fun(**dict1) def fun (add ): add.append('1' ) return add if __name__ == '__main__' : list1=[] list2=fun(list1) print (list1) print (list2)
lambda表达式和匿名函数 用以在一行中定义函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fun = lambda v1,v2 : v1*v2 print (fun(11 ,45 ))fun = lambda v1,v2=20 : v1 * v2 print (fun(10 ))g = [lambda a:a*2 ,lambda b:b*3 ,lambda c:c*4 ] print (g[0 ](6 ),g[1 ](7 ),g[2 ](8 ))
eval函数 功能:将字符串str当成有效的表达式来求值并返回计算结果。
语法: eval(source[, globals[, locals]]) -> value
参数:
source:一个Python表达式或函数compile()返回的代码对象globals:可选。必须是dictionarylocals:可选。任意映射对象
将一个字符串当做代码来执行
eval函数会将字符串当做语句来执行,因此会被注入安全隐患。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 s = "print('abcde')" eval (s)a = 10 b = 20 c = eval ("a+b" ) print (c)dict1 = dict (a=100 ,b=200 ) d = eval ("a+b" ,dict1) print (d)
递归函数 递归(recursion)是一种常见的算法思路,在很多算法中都会用到。比如:深度优先搜索(DFS:Depth First Search)等。
终止条件
表示递归什么时候结束。一般用于返回值,不再调用自己。
递归步骤
把第n步的值和第n-1步相关联。
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
1 2 3 4 5 6 7 8 9 10 11 def my_recursion (n ): print ("start:" + str (n)) if n == 1 : print ("recursion over!" ) else : my_recursion(n - 1 ) print ("end:" + str (n)) my_recursion(3 )
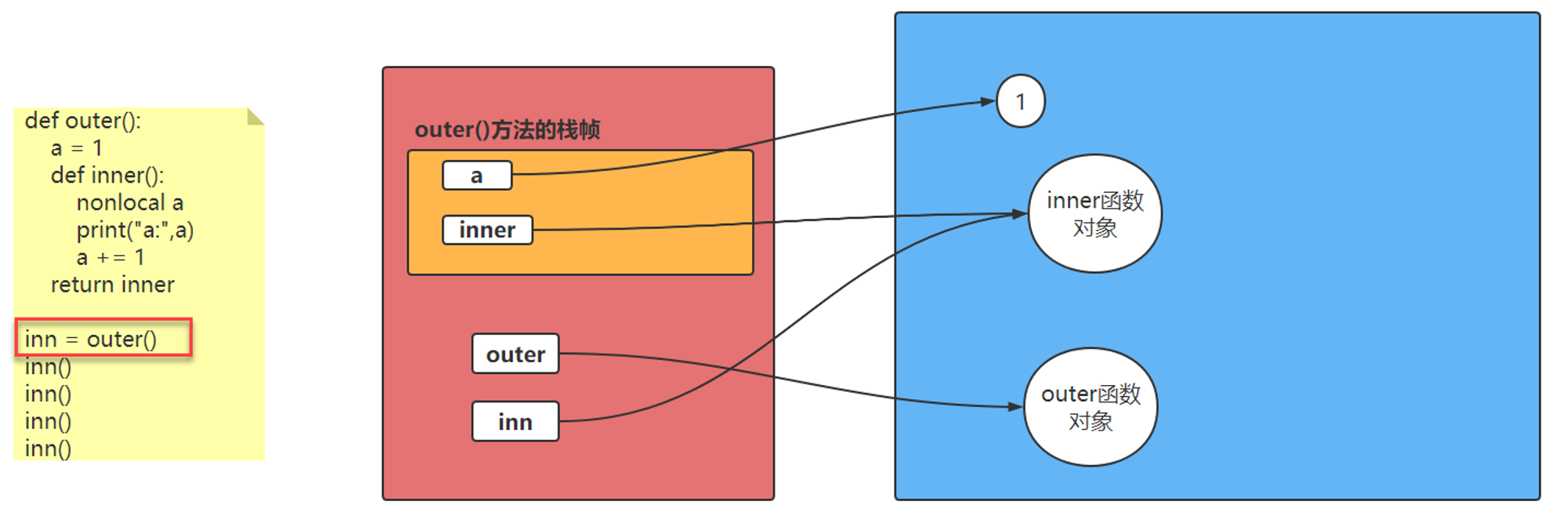
嵌套函数 在函数里定义函数
1 2 3 4 5 6 7 8 9 10 def outer (): print ('outer running...' ) def inner (): print ('inner running...' ) inner() outer()
应用场景:
封装 - 数据隐藏
外部无法访问“嵌套函数”。
贯彻 DRY(Don’t Repeat Yourself) 原则
嵌套函数,可以让我们在函数内部避免重复代码。
闭包
1 2 3 4 5 6 7 8 9 10 11 12 def printName (isChinese,name,familyName ): def inner_print (a,b ): print ("{0} {1}" .format (a,b)) if isChinese: inner_print(familyName,name) else : inner_print(name,familyName) printName(True ,"小七" ,"高" ) printName(False ,"George" ,"Bush" )
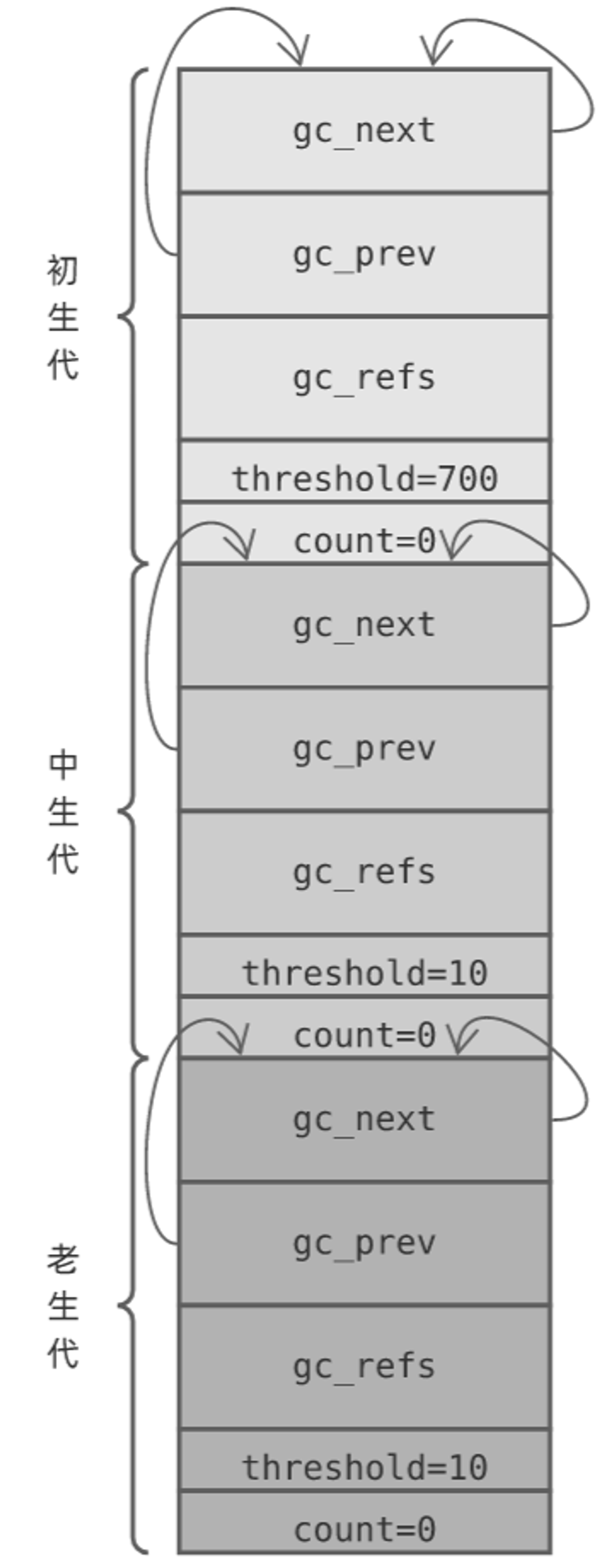
__del__析构方法和垃圾回收机制 Python实现自动的垃圾回收,当对象没有被引用时(引用计数为0),由垃圾回收器调用__del__()。
__del__()称为“析构方法”,用于实现对象被销毁时所需的操作。比如:释放对象占用的资源,例如:打开的文件资源、网络连接等。
也可以通过del删除对象,从而保证调用__del__()。
1 2 3 4 5 6 7 8 9 10 11 class User : def __del__ (self ): print ("User deleted:{0}" .format (self)) p1 =User() p2 =User() del p1print ("结束" )User deleted:<__main__.User object at 0x000001E536E17208 > 结束 User deleted:<__main__.User object at 0x000001E536E17160 >
__call__方法和可调用对象 Python 中,凡是可以将 () 直接应用到自身并执行,都称为可调用对象。
可调用对象包括自定义的函数、Python 内置函数、以及实例对象
该方法使得实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def f1 (): print ("f1" ) f1() class F2 (): pass f2 = F2() f2() class F3 (): def __call__ (self ): print ("f3" ) f3 = F3() f3() 这里就使用了call方法 文言一心举例: 在实例化之后,就可以直接调用实例,此时就会调用实例的父类的__call__方法 class CallableClass : def __init__ (self, value ): self.value = value def __call__ (self, *args, **kwargs ): print (f"Called with {args} and {kwargs} " ) return self.value * 2 instance = CallableClass(5 ) result = instance(3 , 4 , key='value' ) print (result)
面向对象编程 面向过程和面向对象的区别
面向过程和面向对象都是对软件分析、设计和开发的一种思想,它指导着人们以不同的方式去分析、设计和开发软件。C语言是一种典型的面向过程语言,Java是一种典型的面向对象语言。
面向过程适合简单、不需要协作的事务,重点关注如何执行。面向过程时,我们首先思考“怎么按步骤实现?”
面向对象(Oriented-Object)思想更契合人的思维模式。我们首先思考的是”怎么设计这个事物?”。比如思考造车,我们就会先思考“车怎么设计?”,而不是“怎么按步骤造车的问题”。这就是思维方式的转变。
面向对象可以帮助我们从宏观上把握、从整体上分析整个系统。 但是,具体到实现部分的微观操作(就是一个个方法),仍然需要面向过程的思路去处理。
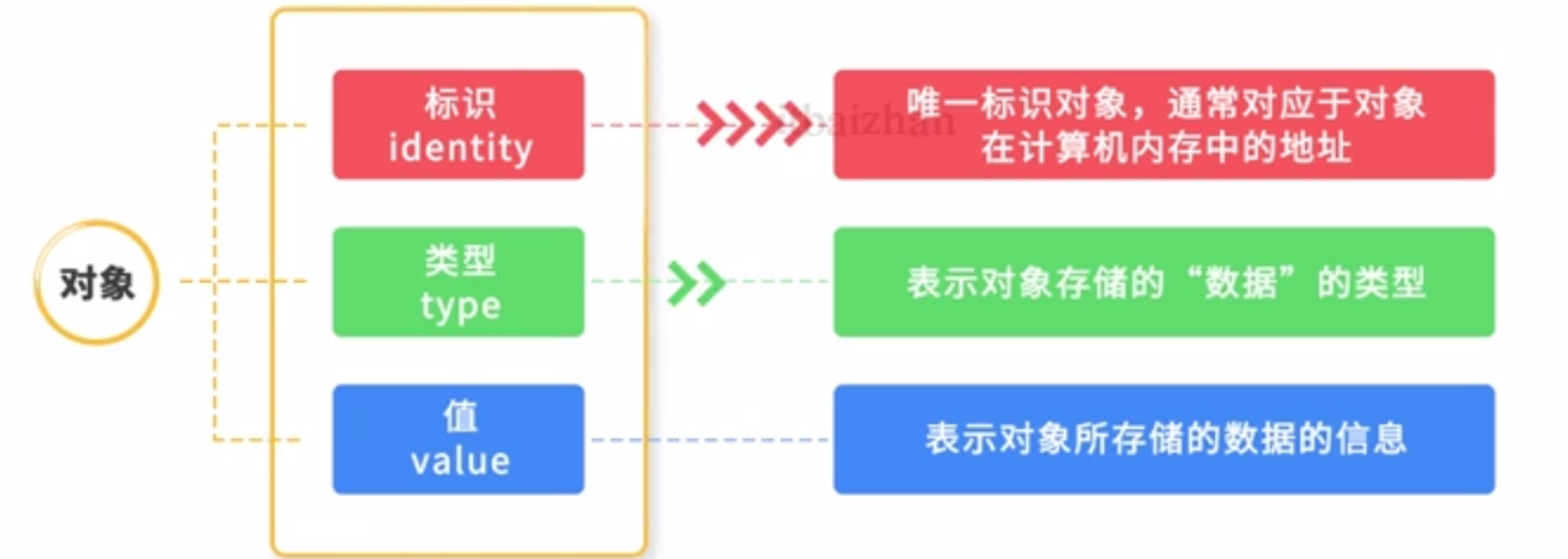
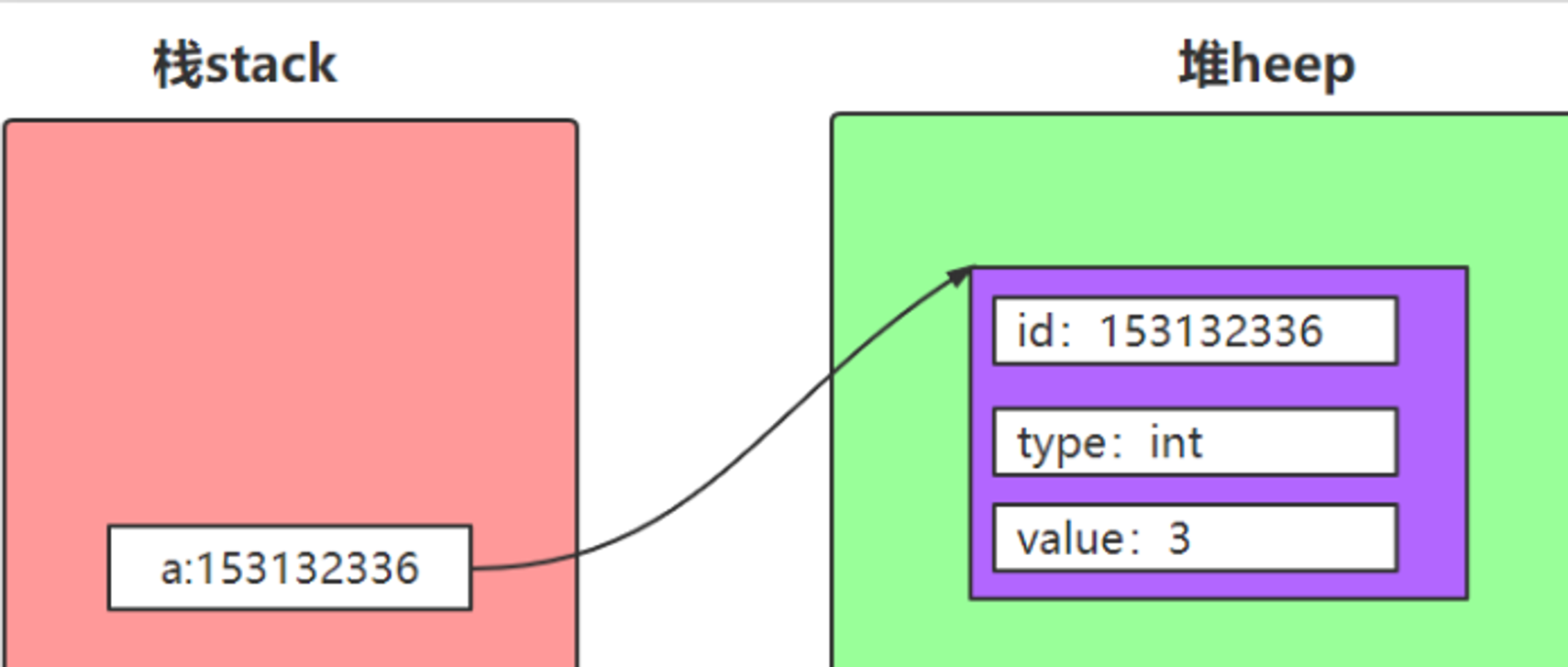
对象的组成 对象由三部分组成:标识、类型、值
对象的标识是这个对象在内存中的地址,通过id方法,来获取对象的标识
1 2 3 var=123 print(type(var))
引用的本质 在Python中,变量也称为:对象的引用(reference)。
变量存储的就是对象的地址:
面向对象的基本概念
类class:为了做区分而创建的一些特性的群体
使用面向对象编程,在做好细分之后,能够更快实现功能,更容易维护,类越细分,对象就越精细
类1 → 对象1,对象2
通过类来定义数据类型的属性(数值)和方法,类将属性和方法打包在一起
类、类的属性、类的方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 举例: 类————管理员、用户 类的属性————是类里的变量。反映该类对象的信息,例如账号、密码、名字等 类的方法————是类里的函数。反映该类对象能做的事,例如账号权限、添加用户、修改密码等,是一种方法,比如list .append,是自己定义的函数 class Ws : pass class XhyClass : pass v1 = Ws() class User_info : def __init__ (self ): self.username = 'ws' self.age = '24' self.password = 'ws111' user1 = User_info() print (user1.password)class User_info : def __init__ (self,username,age,password ): self.username = username self.age = age self.password = password user1 = User_info('ws' ,24 ,'ws111' ) user2 = User_info('xhy' ,23 ,'xhy111' ) print (user1.username)print (user2.password)class User_info : def __init__ (self,name,password,age ): self.name = name self.password = password self.age = age def show (self ): print (self.name, self.password) def show_age (self ): print (self.age) user1 = User_info('ws' ,'ws111' ,age=24 ) user1.show() user1.show_age() class User_info : def __init__ (self,name ): self.name = name def show_age (self ): self.age = 24 print (self.age) user1.show_age() 也可以在实例中新添加类的属性,这个类的属性仅对于那个实例有效
实例方法 实例方法的本质是调用实例自己,如果没有实例则无法调用,这也是最普遍的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class User_info : def __init__ (self,name ): self.name = name def show (self,c ): self.c = c print (c) user1 = User_info('ws' ) user1.show(1 ) user1.show(1 )的本质是User_info.show(user1,1 ) 其他操作: dir (obj)可以获得对象的所有属性、方法obj.__dict__ 对象的属性字典 pass 空语句isinstance (对象,类型) 判断“对象”是不是“指定类型”print (dir (User_info))print (user1.__dict__)print (isinstance (user1,User_info))
类对象、类方法的内存分析 1.类对象A的本质是一个type为’type’的对象,A的value包括它的属性和方法
2.A实例化时,通过构造方法__init__,以A为模板进行创建实例B
3.实例对象B的type为A,B通过A的模板生成属性和方法,作为B的value,其中变量是新的,函数依然指向A的函数
4.在A中定义的属性如果没有被构造,那么这些属性就是A的类属性
实例化的对象,都是通过这一个类对象的信息进行创建
类方法 在类中,无法直接调用实例中的属性和方法;如果要调用,需要将其实例化之后才能调用
类方法可以直接通过类调用方法,因此支持在不实例化的情况下创建并返回类的对象
类方法————首个参数为cls,并且以classmethod装饰的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class User_info : def __init__ (self,name ): self.name = name @classmethod def show (cls ): print ('ws' ) User_info.show() class User_info : def __init__ (self, name, age ): self.name = name self.age = age @classmethod def show_name (cls, age ): print (age) User_info.show_name(24 )
静态方法 静态方法,使用staticmethod装饰,可以直接调用,基本和类无关了。
无法使用类的属性和方法,也无法使用实例属性和方法
1 2 3 4 5 6 7 8 9 class User_info : def __init__ (self, name ): self.name = name @staticmethod def show_name (): print ('11111' ) User_info.show_name()
方法没有重载 如果我们在类体中定义了多个重名的方法,只有最后一个方法有效。
方法的动态性 Python是动态语言,可以动态的为类添加新的方法,或者动态的修改类的已有的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class User : def work (self ): print ('work' ) def play1 (s ): print ('play' ) def work2 (s ): print ('work2' ) User.play = play1 User.work = work2 p1 = User() p1.work() p1.play() ''' work2 play 如果不在函数里加一个s,添加到类中时,就需要添加self参数 如果定义的时候没有添加参数,就会报错 '''
私有属性和私有方法 python对类的成员没有严格的访问控制限制。所谓私有其实是约定的
通常我们约定,两个下划线开头的属性是私有的(private)。其他为公共的(public)。
类内部可以访问私有属性(方法)
类外部不能直接访问私有属性(方法)_类名__私有属性(方法)名”访问私有属性(方法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Wangsheng : __name = 'ws' address = 'sx' def __init__ (self,name,age ): self.name = name self.age = age def output (self ): print (Wangsheng.__name) def __work (self ): print ('work' ) a = Wangsheng('wangsheng' ,'25' ) print (Wangsheng._Wangsheng__name) print (Wangsheng.address) a.output() a._Wangsheng__work()
@property装饰器 如果要限制一些数值的大小,可以使用@property装饰器,将一个方法的调用变成属性调用
在对属性做读操作和写操作的时候使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 修改前: class Example : def __init__ (self,name,age ): self.name = name self.age = age example1 = Example('ws' ,25 ) print (example1.age) example1.age = 18 print (example1.age) 这里可以直接进行修改就很不安全 所以可以将其转变为私有属性 使用私有属性: class Example : def __init__ (self,name,age ): self.name = name self.__age = age def age (self ): return self.__age example1 = Example('ws' ,25 ) print (example1.age())使用装饰器: class Example : def __init__ (self,name,age ): self.name = name self.__age = age @property def age (self ): return self.__age @age.setter def age (self,age ): if 18 <age<25 : self.__age = age else : print ('录入错误' ) example1 = Example('ws' ,25 ) print (example1.age) example1.age = 19 print (example1.age)
属性和方法命名
_xxx:保护成员,不能用from module import *导入,只有类对象和子类对象能访问这些成员
__xxx__:系统定义的特殊成员
__xxx: 类中的私有成员,只有类对象自己能访问,子类对象也不能访问。(但,在类外部可以通过对象名. _类名__xxx这种特殊方式访问。Python不存在严格意义的私有成员)
类相关:
类名首字母大写,多个单词之间采用驼峰原则。
实例名、模块名采用小写,多个单词之间采用下划线隔开
每个类,应紧跟“文档字符串”,说明这个类的作用
可以用空行组织代码,但不能滥用。在类中,使用一个空行隔开方法;模块中,使用两个空行隔开多个类
None变量
None在python中也是对象,type为NoneType,可以将None赋值给任何对象,多个None的对象指向同一个id
None和无论什么想比都是FALSE
if判断时,空列表空字典空元组0等都会转换成FALSE
不能直接创建None类型的对象
继承 子类继承父类之后可以直接使用父类定义好的属性和方法
创建类时,默认的类是object
子类不重写__int__,实例化子类时,会自动调用父类的__int__
子类重写__int__,要使用父类的构造方法,可以使用super关键字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class User (): def __init__ (self,name ): self.name = name def show (self ): print ('111' ) class U001 (User ): def age (self ): print ('123' ) def show (self ): print ('222' ) if __name__ == '__main__' : user1 = U001('ws' ) user1.show() class Person : def __init__ (self,name,age ): print ("Person构造方法" ) self.name = name self.age = age def say_age (self ): print (self.name,"的年龄是:" ,self.age) class Student (Person ): def __init__ (self,name,age,score ): Person.__init__(self,name,age) print ("Student的构造方法" ) self.score = score def say_score (self ): print (self.name,'的分数是:' ,self.score) s1 = Student('王盛' ,25 ,80 ) s1.say_age() s1.say_score() ''' Person构造方法 Student的构造方法 王盛 的年龄是: 25 王盛 的分数是: 80 '''
类成员的继承与重写 成员继承:子类继承了父类除构造方法之外的所有成员 。包括私有属性私有方法
方法的继承与重写与属性基本一致,如果子类重写了父类的方法,使用时就会使用子类的方法
可以通过mro()来查看继承属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 1 、全部保留属性,不新增2 、全部替换,只用自己的3 、保留部分属性,不新增4 、保留部分属性,有新增class User_info : def __init__ (self, username, password, email ): self.username = username self.password = password self.email = email class User (User_info ): pass user1 = User('ws' ,'ws111' ,'1320' ) print (user1.username)class User_info : def __init__ (self, username, password, email ): self.username = username self.password = password self.email = email class User (User_info ): def __init__ (self,age,job ): self.age = age self.job = job user1 = User('ws' ,'ws111' ) print (user1.age)print (user1.username)class User_info : def __init__ (self, username, password, email ): self.username = username self.password = password self.email = email class User (User_info ): def __init__ (self,username,password ): super ().__init__(username=username,password=password,email=None ) if __name__ == '__main__' : user1 = User('ws' ,'ws111' ) print (user1.username) class User_info : def __init__ (self, username, password, email ): self.username = username self.password = password self.email = email class User (User_info ): def __init__ (self,username,password,job ): self.job = job super ().__init__(username=username,password=password,email=None ) if __name__ == '__main__' : user1 = User('ws' ,'ws111' ,'student' ) print (user1.username,user1.job)
object根类 object类是所有类的父类,因此所有的类都有object类的属性和方法。我们显然有必要深入研究一下object类的结构
所有类都有object类的属性和方法
重写__str__()方法 用于返回一个对对象的描述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class User : def __init__ (self,name,age,job ): self.name = name self.age = age self.job = job def __str__ (self ): '''对象转化成一个字符串描述''' print ("重写__str__()方法" ) return "我是{0},{1},是{2}" .format (self.name, self.age, self.job) User1 = User('王盛' ,24 ,'学生' ) print (User1)s = str (User1)
多重继承 Python支持多重继承,一个子类可以有多个“直接父类”。这样,就具备了“多个父类”的特点。但是由于,这样会被“类的整体层次”搞的异常复杂,尽量避免使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class A : def aa (self ): print ('aa' ) class B : def bb (self ): print ('bb' ) class C (A,B): def cc (self ): print ('cc' ) c = C() c.aa() c.bb() c.cc() print (C.mro()) [<class '__main__.C' >, <class '__main__.A' >, <class '__main__.B' >, <class 'object' >] 如果调用C的一个类 在A和B中都有,会先查找C,然后查找A,然后B
super()获得父类定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 调用父类的构造方法: super (子类名称,self).__init__(参数列表)class A : def __init__ (self ): print ("A的构造方法" ) def say (self ): print ("A: " ,self) print ("say AAA" ) class B (A ): def __init__ (self ): super (B,self).__init__() print ("B的构造方法" ) def say (self ): super ().say() print ("say BBB" ) b = B() b.say()
多态 多态(polymorphism)是指同一个方法调用由于对象不同可能会产生不同的行为。
多态需要有继承,只发生在父类和子类之间,需要有重写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Version : def what (self ): print ('Version' ) class V1 (Version ): def what (self ): print ('v1' ) class V2 (Version ): def what (self ): print ('v2' ) class V3 (Version ): def what (self ): print ('v3' ) def fun (object object .what() if __name__ == '__main__' :将v1-3 都实例化 v1 = V1() v2 = V2() v3 = V3() 实例引用方法 fun(v1) fun(v2) fun(v3)
运算符重载、特殊方法 Python的运算符实际上是通过调用对象的特殊方法实现的。
c = a+b和c = a.add (b)是一致的
所以有时候会自己重新对+进行定义
方法
说明
例子
init 构造方法
对象创建和初始化:p = Person()
del 析构方法
对象回收
repr ,str 打印,转换
print(a)
call 函数调用
a()
getattr 点号运算
a.xxx
setattr 属性赋值
a.xxx = value
getitem 索引运算
a[key]
setitem 索引赋值
a[key]=value
len 长度
len(a)
运算符
特殊方法
说明
+
add 加法
-
sub 减法
< <= ==
lt le eq 比较运算符
> >= !=
gt ge ne 比较运算符
^ &
or xor and
<< >>
lshift rshift 左移、右移
* / % //
mul truediv mod floordiv 乘、浮点除、模运算(取余)、整数除
**
pow 指数运算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 重载运算符 class Persion : def __init__ (self,name ): self.name = name def __add__ (self,other ): if isinstance (other,Persion): return "{0},{1}" .format (self.name,other.name) else : return "不是同类对象不能相加" def __mul__ (self,other ): if isinstance (other,int ): return self.name*other else : return "不是同类对象不能相加" p1 = Persion('ws' ) p2 = Persion('xhy' ) x = p1 + p2 print (x)print (p1*3 )
特殊属性
特殊属性
含义
obj.dict
对象的属性字典
obj.class
对象所属的类
class.bases
表示类的父类(多继承时,多个父类放到一个元组中)
class.base
类的父类
class.mro
类层次结构
class.subclasses ()
子类列表
集成与组合 除了继承,“组合”也能实现代码的复用。“组合”核心是“将父类对象作为子类的属性”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class CPU : def calculate (self ): print ("Calculating" ) class Screen : def show (self ): print ("showing" ) class MobilePhone : def __init__ (self,cpu,screen ): self.screen = screen self.cpu = cpu c = CPU() s = Screen() m = MobilePhone(c,s) m.cpu.calculate() m.screen.show()
设计模式-工厂模式与单例模式 设计模式说到底就是使用一种套路
工厂模式 工厂模式实现了创建者和调用者的分离,使用专门的工厂类将选择实现类、创建对象进行统一的管理和控制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class CarFactory : def createCar (self,brand ): if brand == '小米' : return Xiaomi() elif brand == '华为' : return HW() elif brand == 'BYD' : return BYD() else : return "Unknown brand" class Xiaomi : pass class BYD : pass class HW : pass factory = CarFactory() c1 = factory.createCar('小米' ) c2 = factory.createCar('华为' ) c3 = factory.createCar('BYD' )
单例模式 单例模式(Singleton Pattern)的核心作用是确保一个类只有一个实例,并且提供一个访问该实例的全局访问点。
单例模式只生成一个实例对象,减少了对系统资源的开销。当一个对象的产生需要比较多的资源,如读取配置文件、产生其他依赖对象时,可以产生一个“单例对象”,然后永久驻留内存中,从而极大的降低开销。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class MySingleton : __obj = None __init_flag = True def __new__ (cls,*args,**kwargs ): if cls.__obj == None : cls.__obj = object .__new__(cls) return cls.__obj def __init__ (self,name ): if MySingleton.__init_flag is True : print ("初始化第一个对象" ) self.name = name MySingleton.__init_flag = False a = MySingleton('aa' ) print (a)b = MySingleton('bb' ) print (b)
异常处理 常见的异常导致的错误包括:
用户操作相关:类型错误、无效输入、误操作
编程中要尽可能面对各种异常情况,编写全面完整的异常处理逻辑
异常信息包括:
函数体中使用异常处理结构时,尽量不要使用return,在最后使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 例1 : try : print ('1' ) a = 3 /0 print ('2' ) except Exception as e: print ('3' ) print (e) print ('4' ) print ('5' )例2 : while True : try : num = input ('>>' ) if '.' in num: num = float (num) else : num = int (num) **** print (num + 10 ) break except Exception as e: print ('please press number' ) print (e) 例3 : 多except 结构 try : a = input ("被除数" ) b = input ("除数" ) c = float (a)/float (b) print (c) except ZeroDivisionError: print ("除数不能为0" ) except TypeError: print ("类型错误" ) except ValueError: print ("值类型错误" ) except BaseException as e: print (e) print (type (e)) BaseException类包含上面几个小类,如果把它放在最前面,就会全部捕获,无法达成分类的效果 例4 :except ...else try : a = input ("被除数" ) b = input ("除数" ) c = float (a)/float (b) except BaseException as e: print (e) else : print (c) try : pass except Exception as e: pass finally : pass raise Exceptionraise StopIteration常见异常 所有异常类都是从BaseException类的子类,不同的异常类记录不同的异常信息 SyntaxError:语法错误 NameError:尝试访问一个没有申明的变量 ZeroDivisionError:除数为0 错误(零除错误) ValueError:数值错误 AttributeError:访问对象的不存在的属性 TypeError:类型错误 IndexError:索引越界异常 KeyError:字典的关键字不存在 def fun (): while True : try : n1 = input ('Enter student number:' ) n1 = int (n1) if len (str (n1)) == 4 : print ('成功' ) break else : print ('请输入四位数字' ) except ValueError as e: print ('请输入数字' ) if __name__ == '__main__' : fun() def fun (): while True : try : n1 = input ('Enter student number:' ) if not n1.isdigit(): raise ValueError('输入纯数字' ) if len (n1) != 4 : raise ValueError("输入的数字不是4位数" ) else : print ('成功' ) break except ValueError as e: print (e) if __name__ == '__main__' : fun()
异常名称
说明
ArithmeticError
所有数值计算错误的基类
AssertionError
断言语句失败
AttributeError
对象没有这个属性
BaseException
所有异常的基类
DeprecationWarning
关于被弃用的特征的警告
EnvironmentError
操作系统错误的基类
EOFError
没有内建输入,到达EOF 标记
Exception
常规错误的基类
FloatingPointError
浮点计算错误
FutureWarning
关于构造将来语义会有改变的警告
GeneratorExit
生成器(generator)发生异常来通知退出
ImportError
导入模块/对象失败
IndentationError
缩进错误
IndexError
序列中没有此索引(index)
IOError
输入/输出操作失败
KeyboardInterrupt
用户中断执行(通常是输入^C)
KeyError
映射中没有这个键
LookupError
无效数据查询的基类
MemoryError
内存溢出错误(对于Python 解释器不是致命的)
NameError
未声明/初始化对象 (没有属性)
NotImplementedError
尚未实现的方法
OSError
操作系统错误
OverflowError
数值运算超出最大限制
OverflowWarning
旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning
关于特性将会被废弃的警告
ReferenceError
弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError
一般的运行时错误
RuntimeWarning
可疑的运行时行为(runtime behavior)的警告
StandardError
所有的内建标准异常的基类
StopIteration
迭代器没有更多的值
SyntaxError
Python 语法错误
SyntaxWarning
可疑的语法的警告
SystemError
一般的解释器系统错误
SystemExit
解释器请求退出
TabError
Tab 和空格混用
TypeError
对类型无效的操作
UnboundLocalError
访问未初始化的本地变量
UnicodeDecodeError
Unicode 解码时的错误
UnicodeEncodeError
Unicode 编码时错误
UnicodeError
Unicode 相关的错误
UnicodeTranslateError
Unicode 转换时错误
UserWarning
用户代码生成的警告
ValueError
传入无效的参数
Warning
警告的基类
WindowsError
系统调用失败
ZeroDivisionError
除(或取模)零 (所有数据类型)
traceback模块 打印异常信息
1 2 3 4 5 6 7 8 9 10 import traceback try: print ("step1" ) num = 1/0 except: with open("d:/a.log" ,"a" ) as f: traceback.print_exc(file=f)
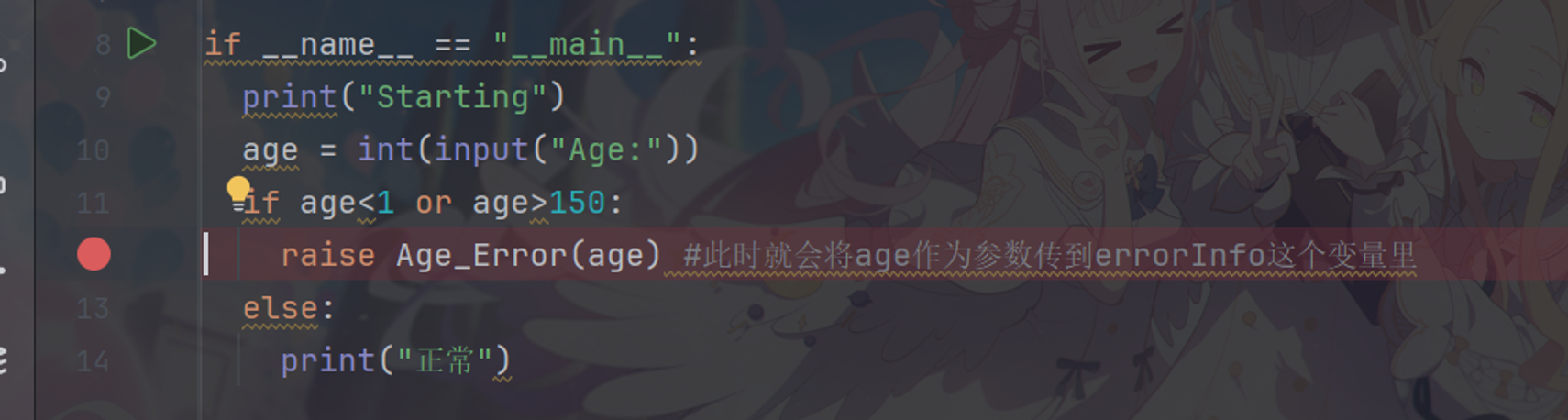
自定义异常类 程序开发中,有时候我们也需要自己定义异常类。自定义异常类一般都是运行时异常,通常继承Exception或其子类即可。命名一般以Error、Exception为后缀。
Python的异常处理机制在需要显示异常信息时会调用异常对象的__str__方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Age_Error(Exception): def __init__(self,errorInfo): Exception.__init__(self) self.errorInfo = errorInfo def __str__(self): return str(self.errorInfo)+"年龄错误" if __name__ == "__main__" : print ("Starting" ) age = int(input("Age:" )) if age<1 or age>150: raise Age_Error(age) else : print ("正常" )
调试与断点 进行调试的核心是设置断点,程序执行到断点时,暂时挂起,停止执行。就像看视频按下停止一样,我们可以详细的观看停止处的每一个细节。
设置断点
调试视图
左侧为“浏览帧”:调试器列出断点处,当前线程正在运行的方法,每个方法对应一个“栈帧”。最上面的是当前断点所处的方法。
右侧为变量值观察区
调试方法:
文件处理 一个完整的程序一般都包括数据的存储和读取;我们在前面写的程序数据都没有进行实际的存储,因此python解释器执行完数据就消失了。实际开发中,我们经常需要从外部存储介质(硬盘、光盘、U盘等)读取数据,或者将程序产生的数据存储到文件中,实现“持久化”保存。
编码问题 ASCII码
是世界上最早最通用的单字节编码系统,主要用来显示现代英语及其他西欧语言。
ASCII码用7位表示,只能表示128个字符。只定义了27=128个字符,用7bit即可完全编码,而一字节8bit的容量是256,所以一字节ASCII的编码最高位总是0。
GB2312
覆盖了汉字的大部分使用率
GBK
扩展了GB2312,在它的基础上又加了更多的汉字,它一共收录了21003个汉字
GB18030
它主要采用单字节、双字节、四字节对字符编码,它是向下兼容GB2312和GBK的,虽然是我国的强制使用标准,但在实际生产中很少用到,用得最多的反而是GBK和GB2312
Unicode
Unicode编码设计成了固定两个字节,所有的字符都用16位(2^16=65536)表示,包括之前只占8位的英文字符等,所以会造成空间的浪费,UNICODE在很长的一段时间内都没有得到推广应用。
UTF-8
UTF编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,UTF编码是不定长编码,每一个字符的长度从1-4个字节不等。其中,英文字母都是用一个字节表示,而汉字使用三个字节。一般项目都会使用UTF-8。
乱码问题
windows操作系统默认的编码是GBK,Linux操作系统默认的编码是UTF-8。当我们用open()时,调用的是操作系统打开的文件,默认的编码是GBK 。
比如,测试写入中文时,如果不指定打开时候的类型,就会默认使用GBK编码,然后使用utf-8打开时,就会乱码。
文本文件和二进制文件 文本文件存储的是文本,python默认为unicode字符集(两个字节表示一个字符,最多可以表示:65536个)
二进制文件把数据内容用“字节”进行存储,无法用记事本打开。必须使用专用的软件解码。常见的有:MP4视频文件、MP3音频文件、JPG图片、doc文档等等
相关模块
名称
说明
io模块
文件流的输入和输出操作 input output
os模块
基本操作系统功能,包括文件操作
glob模块
查找符合特定规则的文件路径名
fnmatch模块
使用模式来匹配文件路径名
fileinput模块
处理多个输入文件
filecmp模块
用于文件的比较
csv模块
用于csv文件处理
pickle和cPickle
用于序列化和反序列化
xml包
用于XML数据处理
bz2、gzip、zipfile、zlib、tarfile
用于处理压缩和解压缩文件(分别对应不同的算法)
创建文件对象open() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 为了对文件进行读写操作,需要先打开文件 python提供了内置函数open 返回的文件对象(需要一个变量来接收) def open (file, mode='r' , buffering=None , encoding=None , errors=None , newline=None , closefd=True ):一般只改mode """ mode: r 只读,默认参数 w 只写,会清空文件内容,如果没有则会创建文件,类似于echo > a 追加模式,如果没有则会创建文件,类似于echo >> x 只写,如果已有文件则会报错,保证文件是第一次创建 + 读写,可读可写,必须与上面的搭配使用 b 二进制模式,用二进制打开,必须与上面的搭配使用 """ file = open ("test1.json" ,mode='r' ,encoding="utf-8" ) file.close() file = open ("test2.json" ,mode='a+' ,encoding="utf-8" ) file.close() file = open ("test1.json" ,mode="wb" ) file.close() file = open ("test1.json" ,mode="w+b" ) file.close() open 了之后的对象需要进行close,close的本质是,将缓冲区的数据写入文件,也可以使用flush()方法 结合with 使用,就可以不需要使用close with open (r"./test.txt" ,"a" ) as f: s = """wangsheng xuehuiying""" f.write(s)
read方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """ 返回在文件中读取到的内容 # def read(self, n: int = -1) -> AnyStr: 默认值为n=-1,输出所有内容 通过修改值,输出n字节 """ file = open ("test.log" ,mode='r' ) print (file.read())print (file.read(50 ))print (file.read(5 ))没有关闭文件时,可以多次读取,每次读取都会从上一次的后面继续读 如果已经读完了,就不会读了 file.close()
readline方法 每次默认读取第一行,可以设置读取多行,用法与read基本一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 file = open ("test.log" ,mode='r' ) print (file.readline())print (file.readline(2 ))print (file.readline(3 ))file.close() 另一种方法: with open (r"./test.txt" ,"r" ,encoding="utf-8" ) as f: for line in f: print (line,end="" ) with open (r"./test.txt" ,"r" ,encoding="utf" ) as f: while True : line = f.readline() if not line: break else : print (line,end="" )
readlines方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 默认返回文件中每行内容组成的列表 file = open ("test.log" ,mode='r' ) print (file.readlines())如果添加参数值少于一行的字符,就会只输出一行,如果大于一行,则会返回两行 file = open ("test.log" ,mode='r' ) print (file.readlines(45 ))print (file.readlines(20 ))练习 为每行末尾增加 序列的井号 with open ('./test.txt' , 'r' ,encoding='utf-8' ) as f: lines = f.readlines() lines2 = [line + "#" + str (index) for index,line in zip (range (1 ,len (lines)+1 ),lines)] print (lines) print (lines2)
write方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 """ write方法——写入一个字符串,且不会自动换行 writelines方法——将序列中的字符串依次写入(输入为列表),且不会自动换行 """ file = open ("test2.json" ,"w+" ,encoding="utf-8" ) file.write("11111" ) file.write("11111\n" ) file.write("11111" ) file.close() file = open ("test2.json" ,"w+" ,encoding="utf-8" ) str = """ qweqwe wsad qews """ file.write(str ) with open (r"./test.txt" ,"w" ) as f: list1 = ["wangsheng\n" ,"xuehuiying\n" ,"qwe" ] f.writelines(list1)
write和read的综合练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 with open('./test.txt' , 'r' ,encoding='utf-8' ) as f: lines = f.readlines() lines2 = [line.rstrip() + "#" + str(index) + "\n" for index,line in zip(range(1,len(lines)+1),lines)] print (lines) print (lines2) with open('./test.txt' ,'w' ,encoding='utf-8' ) as f: f.writelines(lines2)
二进制文件读写 实现图片文件拷贝
1 2 3 4 二进制文件处理流程与文本文件一致,首先要创建文件对象,并制定二进制模式 with open('Mika.png' ,'rb' ) as srcFile,open('MikaMika.png' ,'wb' ) as destFile: for line in srcFile: destFile.write(line)
文件对象的常用属性和方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 name —— 名字 mode —— 打开模式 closed —— 如果关闭,则返回True 模式 说明 r 读模式 w 写模式 a 追加模式 b 二进制模式(可与其他模式组合) + 读写模式(可以其他模式组合) 方法名 说明 read ([size]) 从文件中读取size个字节或字符的内容返回。若省略[size],则读取到文件末尾,即一次读取文件所有内容readline() 从文本文件中读取一行内容 readlines() 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回 write(str) 将字符串str内容写入文件 writelines(s) 将字符串列表s写入文件文件,不添加换行符 seek(offset [,whence ]) 把文件指针移动到新的位置,offset表示相对于whence 的多少个字节的偏移量;offset:off为正往结束方向移动,为负往开始方向移动whence 不同的值代表不同含义:0: 从文件头开始计算(默认值)1:从当前位置开始计算2:从文件尾开始计算 tell() 返回文件指针的当前位置 truncate ([size]) 不论指针在什么位置,只留下指针前size个字节的内容,其余全部删除;如果没有传入size,则当指针当前位置到文件末尾内容全部删除flush() 把缓冲区的内容写入文件,但不关闭文件 close() 把缓冲区内容写入文件,同时关闭文件,释放文件对象相关资源
文件的指针seek() 文件的指针是用来标记位置的,用来做读操作和写操作
比如连续使用read和write,都是因为存在指针来进行标记
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 """ tell方法——查询指针位置,返回指针的位数 位数:在utf-8的编码格式下,1个英文、数字对应1个位数,1个中文对应3个位数 seek方法——移动指针位置 def seek(self, offset: int, whence: int = 0) -> int: offset为偏移量,可以为负数 whence为偏移起始位置,0表示开头,1表示当前,2表示结尾 ——如果要指定whence,则需要以二进制方式打开,否则只能使用0; 移动指针后如果写入内容,会覆盖旧内容; 如果移动指针数不足字符所占位数就会乱码;如果新内容不足旧内容位数也会乱码 """ file = open ("test2.json" ,mode="r+" ,encoding="utf-8" ) print (file.tell())print (file.read(3 ))print (file.tell())file.close() file = open ("test2.json" ,mode="r+b" ) file.seek(3 ,0 ) print (file.tell())file.seek(0 ,1 ) print (file.tell())file.seek(3 ,1 ) print (file.tell())file.write("哈哈" .encode()) 相当于将位数6 开头的两个字符覆盖为哈哈 乱码情况1 : 同样的方法就会乱码,因为指针位数6 时位置在第一个“盛”中间 移动位数不足字符“盛”所占位数 乱码情况2 : 指针位数7 时,输入插入“哈哈”占6 个指针位,但后面“1 王盛”占了7 个指针位 未占满,所以也会乱码
pickle序列化和反序列化 序列化指的是将对象转化成串行化的数据形式,存储到硬盘或网络中
对象的本质是一个存储数据的内存块 ,有时候需要将其保存在硬盘上,或者发送到网络中传输,此时就需要使用对象的序列化与反序列化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 '' ' pickle.dump(obj,file) 将obj写到存储的file中 pickle.undump(file) 从file读取数据,反序列化城对象 ' '' import pickle with open('data.dat' ,'wb' ) as f: name = 'ws' age = 25 score = [100,20,30] resume = {'name' :name, 'age' :age, 'score' :score} pickle.dump(resume,f) with open('data.dat' ,'rb' ) as f: resume = pickle.load(f) print (resume)
CSV文件操作 cvs是逗号分隔符文本文件,常用于数据存储与交换,Excel文件、数据库的导入导出
Excel文件如果另存为csv文件,就是以逗号分隔的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import csv with open(r"d:\a.csv" ) as a: a_csv = csv.reader(a) headers = next(a_csv) print (headers) for row in a_csv: print (row) with open(r"d:\b.csv" ,"w" ) as b: b_csv = csv.writer(b) b_csv.writerow(headers) b_csv.writerows(rows)
os与os.path模块 os模块可以直接对操作系统进行操作,可以直接调用操作系统的可执行文件、命令,直接操作文件、目录等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import osos.system("ping www.baidu.com" ) ''' 方法名 描述 remove(path) 删除指定的文件 rename(src,dest) 重命名文件或目录 stat(path) 返回文件的所有属性 listdir(path) 返回path目录下的文件和目录列表 mkdir(path) 创建目录 makedirs(path1/path2/path3/...) 创建多级目录 rmdir(path) 删除目录 removedirs(path1/path2...) 删除多级目录 getcwd() 返回当前工作目录:current work dir chdir(path) 把path设为当前工作目录 walk() 遍历目录树 sep 当前操作系统所使用的路径分隔符 ''' import osprint (os.name) print (os.sep) print (repr (os.linesep)) a = '3' print (a)print (repr (a)) print (os.stat("my01.py" ))print (os.getcwd()) os.chdir("d:" ) os.mkdir("ws" ) os.rmdir("ws" ) os.makedirs("ws/123/qwe" ) os.rename("ws" ,"xhy" ) dirs = os.listdir("C:/" ) print (dirs)
os.path模块 实现对目录和文件名进行操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 from os import pathprint (__file__)""" abspath方法——返回指定文件的绝对路径 basename方法——返回指定路径的最后一个部分 dirname方法——返回文件的文件夹 exist方法——判断文件或目录是否存在 isdir方法——判断目录是否存在 isfile方法——判断文件是否存在 split方法——将路径分割为dirname与basename组成的元组 splitext——将指定的路径分割为分拣和扩展名组成的元组 join方法——拼接路径 getctime——返回创建时间 getatime——返回最后访问时间 getmtime——返回最后修改时间 walk——遍历 """ print (path.abspath('test.log' ))print (path.basename('./test1.json' ))print (path.dirname('../Study/test1.json' ))print (path.exists('../Study' ))print (path.isdir('../Study' ))print (path.isfile('函数.py' ))print (path.split("/Users/13209/AppData/Local/KOOK/KOOK.exe" ))print (path.splitext('/KOOK/KOOK.exe' ))print (path.join('/ws' ,'xhy/qwe' ))嵌套,动态获取目录 源文件一般在bin 下,但是程序根目录应该在bin 之上,所以需要进行嵌套 import sysfrom os import pathPATH = path.dirname(__file__) sys.path.append(PATH) if __name__ == '__main__' : print (PATH) 切换到上级目录 PATH = path.dirname(path.dirname(path.dirname(__file__))) 列出指定目录下所有的 .py 文件,并输出文件名 import osimport os.pathpath = os.getcwd() file_list = os.listdir(path) print (file_list)for file_name in file_list: pos = file_name.rfind('.' ) if file_name.endswith('.py' ): print (file_name) file_list2 = [file_name for file_name in os.listdir(path) if file_name.endswith('.py' )] for file_name in file_list2: print (file_name)
walk遍历 os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 os.walk(top[, topdown=True [, onerror=None [, followlinks=False ]]]) 其中, top :是要遍历的目录。 topdown :可选, True ,先遍历 top 目录 再遍历子目录。 返回三元组(root、dirs、files): root :当前正在遍历的文件夹本身 dirs :一个列表,该文件夹中所有的目录的名字 files :一个列表,该文件夹中所有的文件的名字 例子: import os path = os.getcwd() for root, dirs, files in os.walk(path, topdown=True ): for name in files: print (os.path.join(root, name)) for name in dirs: print (os.path.join(root, name)) import osimport os.pathdef print_file (path,level ): child_files = os.listdir(path) for file in child_files: file_name = os.path.join(path,file) print ("\t" *level+file_name) if os.path.isdir(file_name): print_file(file_name,level+1 ) print_file(os.path.dirname(os.getcwd()),level=0 )
shutil模块(拷贝与压缩 shutil 模块是python标准库中提供的,主要用来做文件和文件夹的拷
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import shutilshutil.copyfile("a.txt" ,"a_copy.txt" ) 递归拷贝(复制目录 import shutilshutil.copytree("电影/学习" ,"音乐" ,ignore=shutil.ignore_patterns("*.html" ,"*.htm" )) 压缩与解压缩 import shutilimport zipfileshutil.make_archive('目标位置' ,'压缩方式' ,'压缩文件' ) z = zipfile.Zipfile("a.zip" ,"w" ) z.write("a.txt" ) z2 = zipfile.ZipFile("目标文件" ,"r" ) z.write("a.txt" )
模块 为了让一个源码文件中定义的函数,可以被另外一个源码文件所引用,就需要使用模块。一个python源文件就是一个模块
模块:提供现成的函数和对象给需要的源码使用
模块的类型:
模块化编程的流程 模块化编程的一般流程:
设计API,进行功能描述。(设计)
编码实现API中描述的功能。(编码)
在模块中编写测试代码,并消除全局代码。(测试)
使用私有函数实现不被外部客户端调用的模块函数。
下面是一个API的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "" " 本模块用于计算公司员工的薪资 " "" company = "xxxxx" def yearSalary(monthSalary): "" "根据传入的月薪,计算出年薪" "" pass def daySalary(monthSalary): "" "根据传入的月薪,计算出每天的薪资" "" pass "" " 测试 " ""
import加载的模块分为四种类型:
使用python编写的代码.py文件
已被编译为共享库或DLL的C或C++扩展
一组模块的包
使用C编写并链接到python解释器的内置模块
包(package)的概念和结构 当一个项目中有很多个模块时,需要再进行组织。我们将功能类似的模块放到一起,形成了“包”。本质上,“包”就是一个必须有__init__.py的文件夹。
在pycharm中创建包时,会自动创建带有__init__.py文件的包,在不同级的目录下,可以使用不同的级的模块。
导入包的过程本质上是导入了包的__init__.py文件,也就是执行了__init__.py文件,如果在里面import了包,也会被一并导入
1 2 3 4 5 6 7 import * 语句理论上是希望文件系统找出包中所有的子模块,然后导入它们。这可能会花长时间 Python 解决方案是提供一个明确的包索引: 在__init__.py中定义__all__变量: __all__=['moduleA','moduleB'] 不建议使用import *
库 Python中库是借用其他编程语言的概念,没有特别具体的定义。
模块和包侧重于代码组织,有明确的定义。库强调的是功能性,而不是代码组织。
通常将某个功能的“模块的集合”,称为库。
Python标准库的主要功能有
文本处理,包含文本格式化、正则表达式匹配、文本差异计算与合并、Unicode支持,二进制数据处理等功能
文件处理,包含文件操作、创建临时文件、文件压缩与归档、操作配置文件等功能
操作系统功能,包含线程与进程支持、IO复用、日期与时间处理、调用系统函数、日志(logging)等功能
网络通信,包含网络套接字,SSL加密通信、异步网络通信等功能
网络协议,支持HTTP,FTP,SMTP,POP,IMAP,NNTP,XMLRPC等多种网络协议,并提供了编写网络服务器的框架
W3C格式支持,包含HTML,SGML,XML的处理。
其它功能,包括国际化支持、数学运算、HASH、Tkinter等
使用模块 下面代码块对以下一些内容进行了说明:模块的基础操作、主函数的作用、python查找模块的顺序、init .py文件的作用、项目目录的创建以及添加环境变量的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 import test1test1.fun1() import test1 as wsws.fun1() import test1 as ws,os as OS ,json as JSONws.fun1() from test1 import fun1fun1() from test1 import fun1,fun2from asyncio import protocols,tasksfrom asyncio.protocols import BaseProtocolfrom asyncio.protocols import BaseProtocol as xx主函数的作用————将主逻辑与实现区分开 在main中定义的函数,只有当源码作为程序执行时才会执行,在导入时就不会被执行 当文件被当成模块导入时,只会执行main函数以外的函数 python寻找模块的顺序————如何让模块被源码找到 内置模块 环境变量PYTHONPATH指定的模块 标准库,包含了很多有用的模块,例如os、sys等 当前目录:在当前脚本文件所在的目录中查找模块 安装的第三方库,通常是使用pip或其他包管理工具安装的 自己定义模块时,就需要添加__init__.py 可以放入一些备注信息,也可以提供可调用的对象,比如如果在__init__.py定义了函数,那么导入后可以直接使用。 可以将模块包内的成员都引入,使用时就可以使用顶层的模块包进行调用,不需要在用from mod.xxx import xxx的方式了 from v1_1 import v1,v2from v1_1.n1_1 import n1,n2 v1.fun() v2.fun() v1_1.n1() from .n1_1 import * import v1_1v1_1.n1() 1. 将功能不同的代码区分开。比如bin ,db,logs,data等目录bin 目录要包含main.py,写程序主体逻辑2. 要有readme文件,作为变量、函数、类的一些说明文件3. 要写帮助文档,即在函数下加"""""" import sysprint (sys.path)PATH='C:\Users\13209\Desktop' sys.path.append(PATH)
常用模块 re模块 #re模块,正则表达式————用于查找和验证
正则表达式规则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 """" \d 匹配所有十进制数字 \D 匹配所有非数字,包含下划线 \s 匹配所有空白字符,匹配空格 \S 匹配所有非空字符,包括下划线 \w 匹配所有字母,汉字和数字 \W 匹配所有非字母,汉字和数字,包括下划线 """ eg: import restr1 = '[qwesad王]3 214' chazhao = re.search('\d' ,str1) print (chazhao.group())""" $ 结尾 ^ 开头 * 可以出现n次 + 可以出现1次及以上 ?使用勉强模式——使其匹配的尽量少,可以为0 . 匹配除了\n以外的所有单个字符 | 或符,二选一进行匹配 [] """ eg: import restr1 = '[11sw11王11wss1111ws1123]3214' chazhao = re.findall('ws*' ,str1) print (chazhao)('ws+' ,str1) ('ws+?' ,str1) ('ws?' ,str1) ('s.' ,str1) ('王.|32?' ,str1) ('[a-z]' ,str1) ('[a-z0-9A-Z]+' ,str1) ('[^a-z0-9A-Z]+' ,str1) str1 = '[11sw11王11wss1111ws1123]3214' chazhao = re.findall('1{1,3}' ,str1) ('1{3,}' ,str1) ('s1{,3}' ,str1) """ \t 制表符 \n 换行 \r 回车 \f 分页符 \a 报警符 \e 空格符 """ import restr1='\\234 sdqs' chazhao = re.search('\\\\\w+' ,str1) print (str1)print (chazhao.group())str2=r'\213 3124' chazhao2 = re.search(r'\\\w+' ,str2) print (str2)print (chazhao2.group())
正则表达式方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 import restr1 = "/data/NFSdata 192.168.8.0/24(rw,sync)" chazhao = re.match ('NFS' ,str1) print (chazhao)chazhao2 = re.match ('/data' ,str1) print (type (chazhao2)) print (chazhao2.group())chazhao3 = re.search('/NFS\w+' ,str1) print (type (chazhao3)) print (chazhao3.group())chazhao4 = re.findall('[a-z]+' ,str1) print (chazhao4)chazhao4 = re.finditer('[a-z]+' ,str1) for i in chazhao4: print (i) chazhao5 = re.fullmatch('\s+' ,str1) print (chazhao5)str2 = '1234542134' chazhao6 = re.fullmatch('\d+' ,str2) print (chazhao6.group())str1 = '/data/NFSdata 192.168.8.0/24(rw,sync)' str1 = re.sub('\d+' ,'1' ,str1) print (str1)str1 = '/data/NFSdata 192.168.8.0/24(rw,sync)' list1 = re.split('192.168.8.0/24' ,str1,maxsplit=0 ) print (list1)str1 = '/data/NFSdata 192.168.8.0/24(rw,sync)' chazhao = re.search('(.*)\s(.*)\((.*)\)' ,str1) print (chazhao)print (chazhao.group(0 )) print (chazhao.group(1 )) print (chazhao.group(2 )) print (chazhao.group(3 ))print (chazhao.groups())chazhao2 = re.search('(?P<path>.*)\s(?P<ip>.*)\((?P<mod>.*)\)' ,str1) print (chazhao2.groupdict())str1 = '1234567qwerty' chazhao = re.search('\d+' ,str1) print (chazhao.start())print (chazhao.end())print (chazhao.span())chazhao2 = re.search('[a-z]+' ,str1) print (chazhao2.start())print (chazhao2.end())print (chazhao2.span())
常用模块random random伪随机数模块
常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import randomprint (random.random())print (random.uniform(1.5 ,1.6 )) print (random.randint(1234 ,42156 )) print (random.randrange(1 ,200 ,10 )) print (random.choice([1 ,2 ,5 ,846 ,1234 ,614 ]))list1 = [1 ,2 ,3 ,4 ,5 ] random.shuffle(list1) print (list1)list1 = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ] list2 = random.sample(list1,5 ) print (list2)
常用模块-JSON JSON是一种轻量级的数据交换格式,可以用以给程序之间交换数据
JSON为多种语言设计了接口,是一种“通用文本”
JSON的数据存储有两种格式:键值对、数组
常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import jsondict1 = {'name' :'王盛' } filepro=open ('test1.json' ,'w' ) json.dump(dict1,filepro,ensure_ascii=True ) json.dump(dict1,filepro,ensure_ascii=False ) json.dump(dict1,filepro,ensure_ascii=False ,indent=2 ) filepro.close() file=open ('test1.json' , 'r' ) dict1 = json.load(file) print (dict1)
常用模块-logging 用于在程序中生成日志
日志有等级区分:
logging.basicConfig方法常用传参 默认会处理WARNING等级以上的错误,1级和2级的错误不会输出到python控制台
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import logginglogging.debug('debug' ) logging.warning('warning' ) logging.basicConfig(filename='test.log' ,filemode='a' ) logging.warning('warning' ) """ 当filename='a',表示为追加进日志文件 当filemode='w',表示清空日志文件后再添加 """ logging.basicConfig(filename='test.log' ,filemode='w' ,level=logging.DEBUG) logging.debug('debug' ) """ %(asctime)s 精确到毫秒 %(name)s 使用的记录器名称,默认root %(filename)s 日志输出的模块名 %(funcName)s 日志输出的函数名 %(message)s 日志信息 %(levelname)s 日志等级 %(lineno)s 日志所在行号 %(levelno)s 日志等级 10 20 30 40 50 %(pathname)s 日志输出的完整路径 %(process)s 进程ID %(processName)s 进程名 %(thread)s 线程ID """ format1 = '%(levelname)s - %(asctime)s - 第%(lineno)s行:%(message)s' logging.basicConfig(filename='test.log' ,filemode='a' ,level=logging.DEBUG,format =format1) logging.debug('出现错误' ) import logginglogging.basicConfig( filename="test.log" , format ="%(asctime)s:%(message)s" , level=logging.DEBUG ) logging.debug("debug" ) logging.basicConfig( filename="test.log" , format ="%(asctime)s:%(message)s" , datefmt="%Y-%m-%d-%H:%M:%S" , level=logging.DEBUG ) logging.debug("debug" )
日志流常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import logging""" 日志流模块组件 记录器Logger——提供api 处理程序Handler——创建的日志发到合适的目的地 过滤器Filter——提供日志的控制工具 格式化程序Formatter——日志的输出格式 logger记录器方法: xx = logging.getLogger() 创建记录器 logger.setLevel(logging.DEBUG) 设置告警级别 logger.addHandler(handler) 添加处理器 logger.removeHandler(handler) 移除处理器 handler处理器方法: handler.setLevel(logging.DEBUG) 设置告警级别 handler.setFormatter(formatter) 添加格式化程序 handler.addFilter(filter) 添加过滤器 handler.removeFilter(filter) 移除过滤器 formatter格式化程序方法: fmt = '%(asctime)s - %(levelname)s - %(message)s' xx = logging.Formatter(fmt) 创建格式化程 """ logger = logging.getLogger() logger.setLevel(logging.DEBUG) sh = logging.StreamHandler() fh = logging.FileHandler(filename='test.log' ,encoding='utf-8' ) sh.setLevel(logging.ERROR) fh.setLevel(logging.INFO) logger.addHandler(sh) logger.addHandler(fh) format1 = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s" ) sh.setFormatter(format1) fh.setFormatter(format1) logger.info("logger" ) import loggingdef log_fun (filename ): logger = logging.getLogger() logger.setLevel(logging.DEBUG) fh = logging.FileHandler(filename=filename,encoding='utf-8' ) logger.addHandler(fh) format1 = logging.Formatter('("%(asctime)s - %(levelname)s - %(message)s")' ) fh.setFormatter(format1) return logger if __name__ == '__main__' : logger = log_fun('test.log' ) logger.info('test' )
常用模块-time和datetime time模块 是一种主要用来读取和处理时间戳的模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 import timeprint (time.time())time1=time.time() for i in range (100000 ): print ("" ) print (time.time()-time1)print ("1" )time.sleep(3 ) print ("2" )""" 将所有信息用关键字的方式返回: 没有传参时,返回当前时间戳的信息 """ print (time.localtime())print (time.localtime(1123456 ))print (time.localtime(time1))print (time.mktime(time.localtime()))import time""" format参照表: %y 两位数年份 %Y 四位数年份 %m 月份 %d 月份中的天数 %H 24小时制小时 %I 12小时制小时 %M 分钟数 %S 秒 %a 本地简化星期名,如Tue、Wed等 %A 本地完整星期名 %b 本地简化月份名 %B 本地完整月份名 %c 本地完整的周期、日期、时间、年份表示 %j 一年内的第几天 %p 本地AM或PM表示符,如AM,PM %U 第几个星期0-53 %w 星期数0-6 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 时区名称 %% %号 """ print (time.localtime())print (time.strftime("%Y-%m-%d %H:%M:%S" ,time.localtime()))print (time.strptime("2024-02-27" , "%Y-%m-%d" ))
datetime模块 不涉及时间戳的,正常处理时间的模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 """ datetime中的五个成员类 date——日期对象,常用属性year,month,day time——时间对象 datetime——是上面两个的集合 timedelta——时间间隔对象 tzinfo——时区信息对象 """ """ #import datetime from datetime import date,time,datetime,timedelta 如果需要同时使用import time,后面导入的函数会覆盖前面导入的 可以设置别名 from datetime import date,time as times,datetime,timedelta """
date类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from datetime import datedate1 = date(2024 ,2 ,27 ) print (date1)print (type (date1)) date1 = date(2024 ,2 ,27 ) print (date1.year,date1.month,date1.day)print (date.today())print (type (date.today()))print (date1.isocalendar())print (date1.isoweekday())print (date1.isoformat())print (type (date1.isoformat()))date1 = date1.replace(year=2077 ) print (date1)print (date.fromisoformat("2024-02-27" ))print (type (date.fromisoformat("2024-02-27" )))date1 = date(2024 ,2 ,27 ) print (date1.timetuple())
datetime类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 datetime同时具有date和time的属性,是他俩的总和 from datetime import date,time,datetime,timedeltadate1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) print (date1)print (datetime.fromtimestamp(123456456 ))print (datetime.utcfromtimestamp(123456456 ))print (datetime.now())print (datetime.utcnow())date1 = date(2024 ,2 ,28 ) time1 = time(1 ,2 ,3 ,) print (datetime.combine(date1,time1))print (datetime.fromisoformat("2024-02-28 00:00:00" ))print (type (datetime.fromisoformat("2024-02-28 00:00:00" )))date1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) print (date1.timetuple())print (date1.utctimetuple()) date1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) print (date1.timestamp())date1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) print (date1.date())print (date1.time())date1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) date1 = date1.replace(second=59 ) print (date1)print (date1.isoformat())print (datetime.today())print (date.today().weekday())print (date.today().isoweekday())date1 = datetime(year=2024 ,month=2 ,day=27 ,hour=1 ,minute=2 ) print (date1.strftime("%Y-%m-%d" ))date2 = date1.strftime("%Y-%m-%d" ) print (date1.strptime(date2, '%Y-%m-%d' ))print (type (date1.strptime(date2, '%Y-%m-%d' )))
timedelta类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from datetime import date,time,datetime,timedeltatd1 = timedelta(hours=240 ,minutes=20 ,milliseconds=10 ) print (td1) print (td1.days)print (td1.seconds)print (td1.microseconds)datetime1 = datetime(year=2024 ,month=2 ,day=28 ) datetime2 = datetime(year=2025 ,month=2 ,day=28 ) print (datetime2 - datetime1) td2=timedelta(hours=10 ) print (datetime1 - td2) print (datetime1 + td2)
并发编程 一些概念 串行并行和并发
串行(serial):一个CPU上,按顺序完成多个任务
并行(parallelism):指的是任务数小于等于cpu核数,即任务一起执行
并发(concurrency):一个CPU采用时间片管理方式,交替的处理多个任务。一般是是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
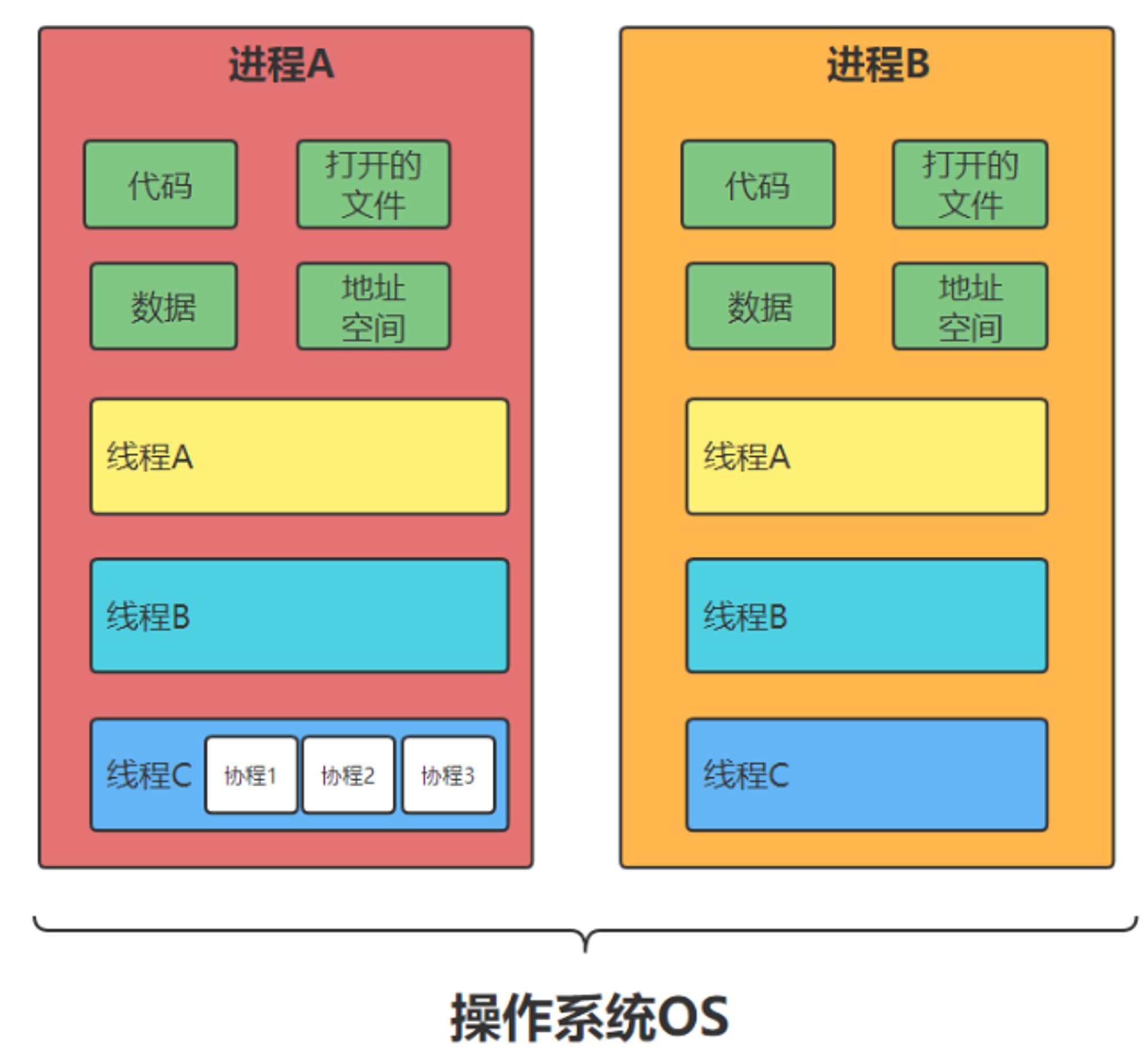
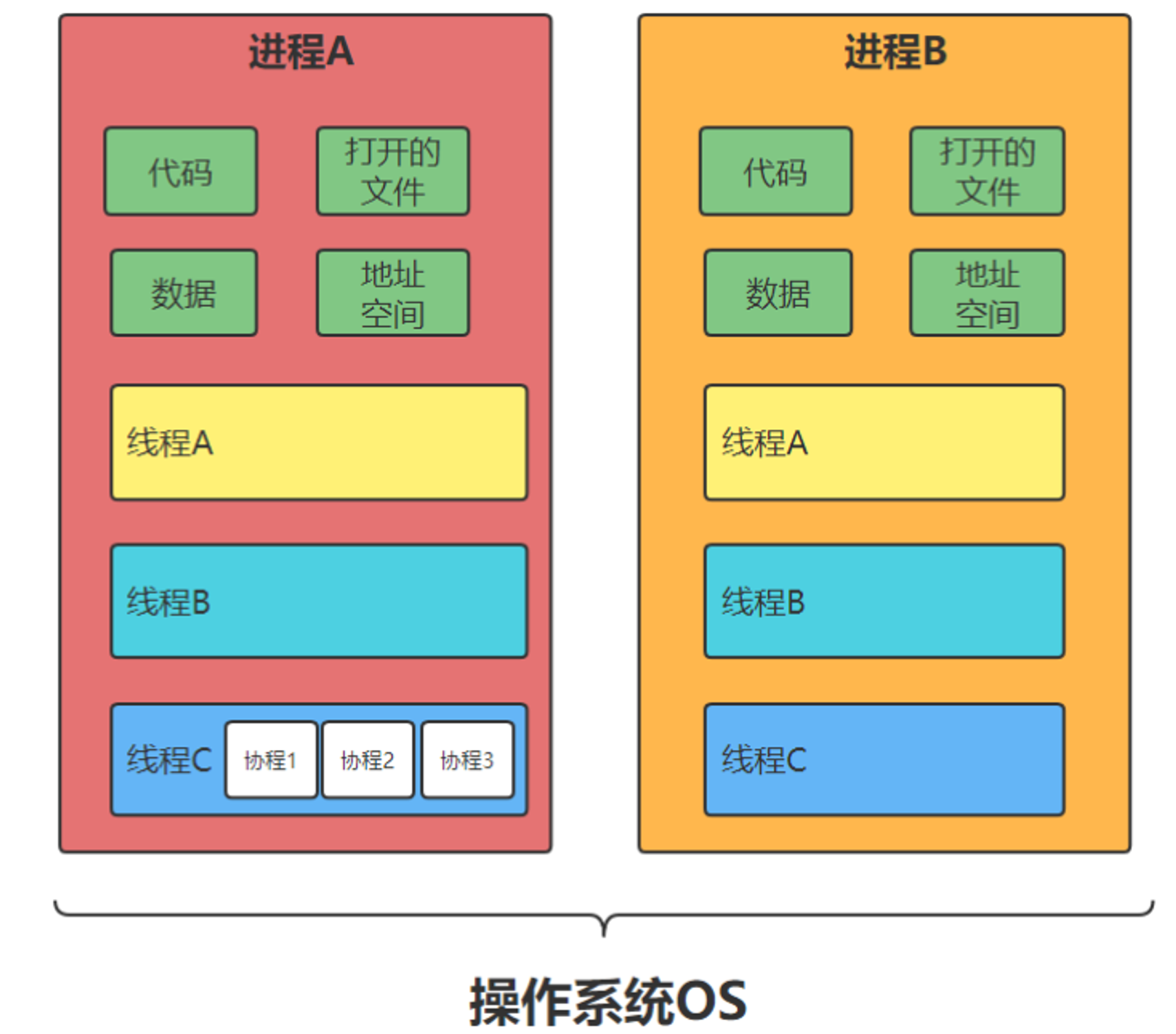
线程、进程和协程
进程(Process):拥有自己独立的堆和栈,既不共享堆,也不共享栈,进程由操作系统调度;进程切换需要的资源很最大,效率低
线程(Thread):拥有自己独立的栈和共享的堆,共享堆,不共享栈,标准线程由操作系统调度;线程切换需要的资源一般,效率一般
协程(coroutine):拥有自己独立的栈和共享的堆,共享堆,不共享栈,协程由程序员在协程的代码里显示调度;协程切换任务资源很小,效率高
同步与异步
同步(synchronous):A调用B,等待B返回结果后,A继续执行
异步(asynchronous ):A调用B,A继续执行,不等待B返回结果;B有结果了,通知A,A再做处理。
线程
线程(Thread) 是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
拥有自己独立的栈和共享的堆,共享堆,不共享栈,标准线程由操作系统调度;
调度和切换:线程上下文切换比进程上下文切换要快得多。
线程的创建方式 Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
创建方式有两种
1.方法包装
线程的执行统一通过start()方法
方法包装创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from threading import Thread from time import sleep def fun1(name): print (f"{name}启动!" ) for i in range(3): print (f"{name}启动{i}秒" ) sleep (1) print (f"{name}结束" ) if __name__ == '__main__' : print ("主线程" ) t1 = Thread(target=fun1,args=("线程1" ,)) t2 = Thread(target=fun1,args=("线程2" ,)) t1.start() t2.start() print ("主线程结束" ) 主线程启动 线程1启动! 线程1启动0秒 线程2启动!主线程结束 线程2启动0秒 线程2启动1秒线程1启动1秒 线程2启动2秒线程1启动2秒 线程1结束线程2结束 可以看出这三个线程都是独立的,互不干扰
类包装创建线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from threading import Thread from time import sleep class NewThread(Thread): def __init__(self,name): Thread.__init__(self) self.name = name def run(self): print (f"{self.name}启动!" ) for i in range(3): print (f"{self.name}启动{i}秒" ) sleep (1) print (f"{self.name}结束" ) if __name__ == '__main__' : print ("主线程开始" ) t1 = NewThread("t1" ) t2 = NewThread("t2" ) t1.start() t2.start() print ("主线程结束" ) 主线程开始 t1启动! t1启动0秒 t2启动! t2启动0秒 主线程结束 t1启动1秒t2启动1秒 t1启动2秒t2启动2秒 t2结束t1结束
join()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 等待子线程结束后,再结束主线程 from threading import Thread from time import sleep class NewThread(Thread): def __init__(self,name): Thread.__init__(self) self.name = name def run(self): print (f"{self.name}启动!" ) for i in range(3): print (f"{self.name}启动{i}秒" ) sleep (1) print (f"{self.name}结束" ) if __name__ == '__main__' : print ("主线程开始" ) t1 = NewThread("t1" ) t2 = NewThread("t2" ) t1.start() t2.start() t1.join() t2.join() print ("主线程结束" ) 主线程开始 t1启动! t1启动0秒 t2启动! t2启动0秒 t1启动1秒 t2启动1秒 t1启动2秒 t2启动2秒 t1结束 t2结束 主线程结束
守护线程
它的生命周期与主线程一致。主线程死亡,它也就随之死亡
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from threading import Thread from time import sleep class NewThread(Thread): def __init__(self,name): Thread.__init__(self) self.name = name def run(self): for i in range(3): print (f"{self.name}{i}" ) sleep (1) if __name__ == '__main__' : print ("主线程开始" ) t1 = NewThread(name="t1" ) t1.daemon = True t1.start() print ("主线程结束" ) 主线程开始 t10主线程结束
GIL全局锁问题 Python的线程无论是几核的CPU,都是只有单线程的。这是一个设计的缺陷
Python Global Interpreter Lock
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
线程同步与互斥锁 处理多线程问题时,多个线程访问同一个对象,并且某些线程还想修改这个对象。 这时候,我们就需要用到“线程同步”。 线程同步其实就是一种等待机制,多个需要同时访问此对象的线程进入这个对象的等待池形成队列,等待前面的线程使用完毕后,下一个线程再使用。
使线程内的内容不发生冲突
不加锁的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from threading import Thread from time import sleep class Count: def __init__(self,money,name): self.money = money self.name = name class Draw(Thread): def __init__(self,change,account): Thread.__init__(self) self.account = account self.change = change self.expenseTotal = 0 def run(self): if self.account.money < self.change: return sleep (1) self.account.money -= self.change self.expenseTotal += self.change print (f"账户:{self.account.name},余额:{self.account.money},共取了:{self.expenseTotal}\n" ) if __name__ == '__main__' : a1 = Count(100,"王盛" ) change1 = Draw(80,a1) change2 = Draw(80,a1) change1.start() change2.start() 钱直接被扣成负的了
使用互斥锁
互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。多个线程一起去抢互斥锁 ,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁。
互斥锁特点
必须使用同一个锁对象
互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
使用互斥锁会影响代码的执行效率
同时持有多把锁,容易出现死锁的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 在上面的案例中,就要保证判断和取钱要在一个线程中不能中断 from threading import Thread,Lock from time import sleep class Count: def __init__(self,money,name): self.money = money self.name = name class Draw(Thread): def __init__(self,change,account): Thread.__init__(self) self.account = account self.change = change self.expenseTotal = 0 def run(self): lock1.acquire() if self.account.money < self.change: print ("余额不足" ) return sleep (1) self.account.money -= self.change self.expenseTotal += self.change lock1.release() print (f"账户:{self.account.name},余额:{self.account.money},共取了:{self.expenseTotal}\n" ) if __name__ == '__main__' : a1 = Count(100,"王盛" ) lock1 = Lock() change1 = Draw(80,a1) change2 = Draw(80,a1) change1.start() change2.start() acquire和release方法之间的代码同一时刻只能有一个线程去操作 如果在调用acquire方法的时候 其他线程已经使用了这个互斥锁,那么此时acquire方法会堵塞,直到这个互斥锁释放后才能再次上锁。
死锁问题 在多线程程序中,死锁问题很大一部分是由于一个线程同时获取多个锁造成。比如一个线程同时需要A和B锁才能执行,但B锁被被人使用了,并且也需要A锁。
死锁是由于“同步块需要同时持有多个锁造成”的,要解决这个问题,思路很简单,就是:同一个代码块,不要同时持有两个对象锁。
信号量semaphore 应用场景:
底层原理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from threading import Semaphore,Thread from time import sleep def home(name,se): se.acquire() print (f"{name}进入房间" ) sleep (2) print (f"{name}离开房间" ) se.release() if __name__ == '__main__' : se = Semaphore(2) for i in range(1,5): t = Thread(target=home, args=(f"第{i}个人" ,se)) t.start() 第1个人进入房间 第2个人进入房间 第1个人离开房间 第3个人进入房间 第2个人离开房间 第4个人进入房间 第4个人离开房间第3个人离开房间
事件event对象 Event 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,event 对象中的信号标志被设置假。如果有线程等待一个 event 对象,而这个 event 对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。
方法名
说明
event.wait(timeout=None)
调用该方法的线程会被阻塞,如果设置了timeout参数,超时后,线程会停止阻塞继续执行;
event.set()
将event的标志设置为True,调用wait方法的所有线程将被唤醒
event.clear()
将event的标志设置为False,调用wait方法的所有线程将被阻塞
event.is_set()
判断event的标志是否为True
生产者与消费者模型 生产者指的是负责生产数据的模块(这里模块可能是:方法、对象、线程、进程)
消费者指的是负责处理数据的模块(这里模块可能是:方法、对象、线程、进程)
消费者不能直接使用生产者的数据,它们之间有个“缓冲区”。生产者将生产好的数据放入“缓冲区”,消费者从“缓冲区”拿要处理的数据。
缓冲区是实现并发的核心,缓冲区的设置有3个好处:
实现线程的并发协作
有了缓冲区以后,生产者线程只需要往缓冲区里面放置数据,而不需要管消费者消费的情况;同样,消费者只需要从缓冲区拿数据处理即可,也不需要管生产者生产的情况。 这样,就从逻辑上实现了“生产者线程”和“消费者线程”的分离。
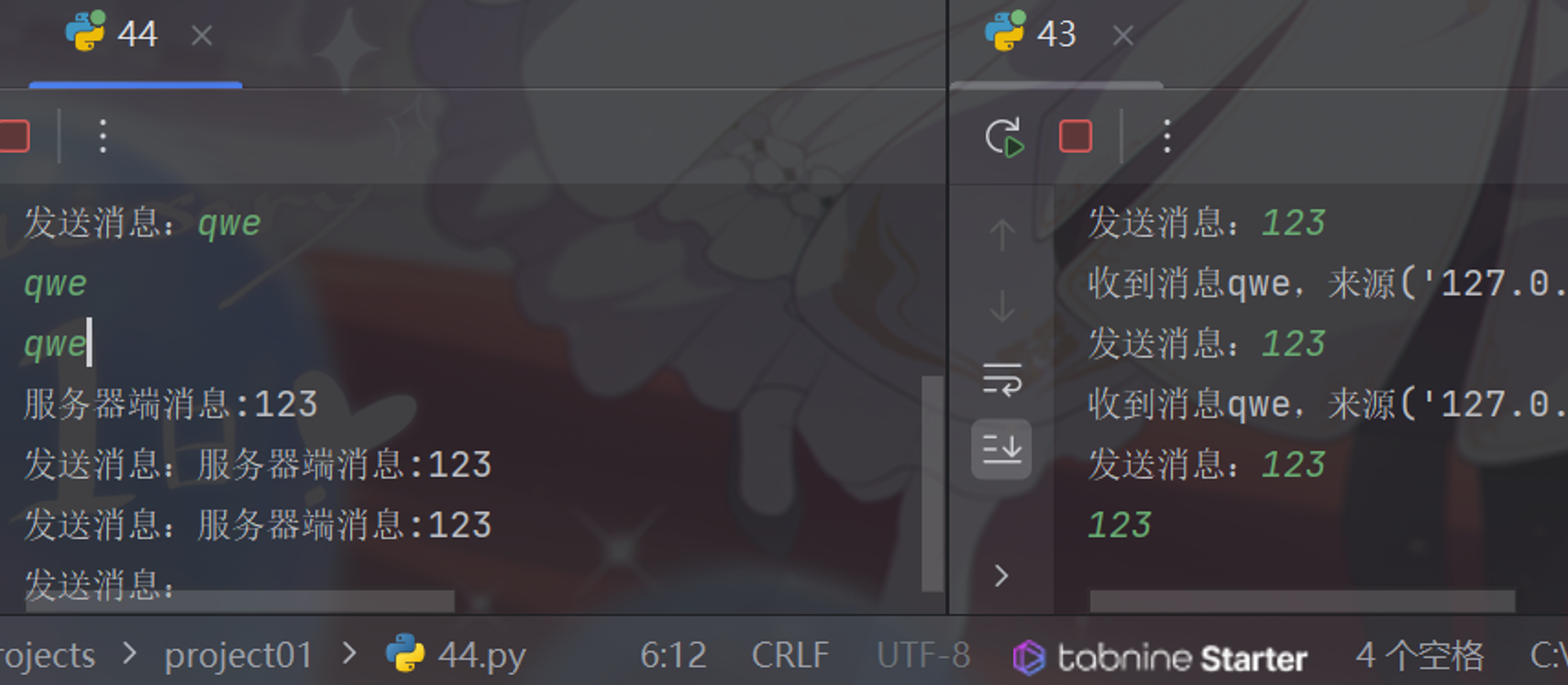
缓冲区、线程通信——Queue对象
使用queue 库中的队列。创建一个被多个线程共享的 Queue 对象,这些线程通过使用 put() 和 get()操作来向队列中添加或者删除元素
通过这样的方式进行线程之间的通信
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from queue import Queue from time import sleep from threading import Thread def producer(): num = 1 while True: if queue.qsize()<=5: print (f"生产第{num}个" ) queue.put(f"第{num}个" ) num += 1 else : print ("缓冲区已满" ) sleep (2) def consumer(): while True: print (f"消费{queue.get()}" ) sleep (3) if __name__ == '__main__' : queue = Queue() t1 = Thread(target=producer) t2 = Thread(target=consumer) t1.start() t2.start() 生产第1个 消费第1个 生产第2个 消费第2个 生产第3个 消费第3个
进程 进程(Process):拥有自己独立的堆和栈,既不共享堆,也不共享栈,进程由操作系统调度;进程切换需要的资源很最大,效率低。对于操作系统来说,一个任务就是一个进程。
特点
可以使用计算机多核,进行任务的并行执行,提高执行效率
运行不受其他进程影响,创建方便
空间独立,数据安全
进程的创建和删除消耗的系统资源较多
进程的创建 也分为类包装与方法包装两种
Python的标准库提供了模块multiprocessing
方法创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import osfrom multiprocessing import Processfrom time import sleepdef fun1 (name ): print (f"进程{name} 开始" ) print (f"当前进程ID{os.getpid()} " ) print (f"父进程ID{os.getppid()} " ) sleep(3 ) print (f"进程{name} 结束" ) if __name__ == '__main__' : print (f"当前进程ID{os.getpid()} " ) p1 = Process(target=fun1,args=("p1" ,)) p2 = Process(target=fun1,args=("p2" ,)) p1.start() p2.start() ''' 当前进程ID27652 进程p1开始 当前进程ID26476 进程p2开始 当前进程ID27660 父进程ID27652 父进程ID27652 进程p1结束 进程p2结束 '''
类创建
与Thread类创建线程差不多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from multiprocessing import Processfrom time import sleepclass MyProcess (Process ): def __init__ (self,name ): Process.__init__(self) self.name = name def run (self ): print (f"进程{self.name} Running" ) sleep(3 ) print (f"进程{self.name} stoping" ) if __name__ == '__main__' : p1 = MyProcess("p1" ) p2 = MyProcess("p2" ) p1.start() p2.start() ''' 进程p1Running 进程p2Running 进程p1stoping 进程p2stoping '''
进程通信 使用queue队列实现进程通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from multiprocessing import Process, Queueclass MyProcess (Process ): def __init__ (self,name,mq ): Process.__init__(self) self.name = name self.mq = mq def run (self ): print (f"进程{self.name} 开始" ) print (f"取得数据{self.mq.get()} " ) self.mq.put(self.name) print (f"进程{self.name} 结束" ) if __name__ == '__main__' : mq = Queue() mq.put("1" ) mq.put("2" ) mq.put("3" ) p_list = [] for i in range (3 ): p = MyProcess(f"p{i} " ,mq) p_list.append(p) for p in p_list: p.start() for p in p_list: p.join() print (mq.get()) print (mq.get()) print (mq.get()) """ 进程p0开始 取得数据1 进程p0结束 进程p1开始 取得数据2 进程p1结束 进程p2开始 取得数据3 进程p2结束 p0 p1 p2 """
pipe管道实现进程通信 Pipe方法返回(conn1, conn2)代表一个管道的两个端。
若duplex参数为True(默认值),那么这个参数是全双工模式
例:在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。如果管道已经被关闭,那么recv方法会抛出EOFError。
总的来说用得不多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import multiprocessing from time import sleep def func1(conn1): sub_info = "这是conn1端" print (f"进程1--{multiprocessing.current_process().pid}发送数据:{sub_info}" ) sleep (1) conn1.send(sub_info) print (f"来自进程2:{conn1.recv()}" ) sleep (1) def func2(conn2): sub_info = "这是conn2端" print (f"进程2--{multiprocessing.current_process().pid}发送数据:{sub_info}" ) sleep (1) conn2.send(sub_info) print (f"来自进程1:{conn2.recv()}\n" ) sleep (1) if __name__ == '__main__' : conn1,conn2 = multiprocessing.Pipe() process1 = multiprocessing.Process(target=func1,args=(conn1,)) process2 = multiprocessing.Process(target=func2,args=(conn2,)) process1.start() process2.start() '' ' 进程1--32748发送数据:这是conn1端 进程2--14432发送数据:这是conn2端 来自进程2:这是conn2端 来自进程1:这是conn1端 ' ''
manager管理器实现进程通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from multiprocessing import Manager, Process def fun1(name,m_list,m_dict): m_dict['name'] = "ws" m_list.append("hello") if __name__ == '__main__': with Manager() as mgr: m_list = mgr.list() m_dict = mgr.dict() m_list.append('Hello!!') p1 = Process(target=fun1, args=('p1', m_list, m_dict)) p1.start() p1.join() print(m_list) print(m_dict)
进程池 进程池可以提供指定数量的进程给用户使用,即当有新的请求提交到进程池中时,如果池未满,则会创建一个新的进程用来执行该请求;反之,如果池中的进程数已经达到规定最大值,那么该请求就会等待,只要池中有进程空闲下来,该请求就能得到执行。
相当于定义了进程的上限数量
这几个进程的进程号是一致的,用完就会还回去
提高效率,节省开辟进程和开辟内存空间的时间及销毁进程的时间
节省内存空间
类/方法
功能
参数
Pool(processes)
创建进程池对象
processes表示进程池中有多少进程
pool.apply_async(func,args,kwds)
异步执行 ;将事件放入到进程池队列
func 事件函数 args 以元组形式给func传参kwds 以字典形式给func传参 返回值:返回一个代表进程池事件的对象,通过返回值的get方法可以得到事件函数的返回值
pool.apply(func,args,kwds)
同步执行;将事件放入到进程池队列
func 事件函数 args 以元组形式给func传参 kwds 以字典形式给func传参
pool.close()
关闭进程池
pool.join()
回收进程池
pool.map(func,iter)
类似于python的map函数,将要做的事件放入进程池
func 要执行的函数 iter 迭代对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from multiprocessing import Pool import os from time import sleep def func1(name): print(f"当前进程的ID:{os.getpid()},{name}") sleep(2) return name def func2(args): print(args) if __name__ == "__main__": pool = Pool(5) pool.apply_async(func = func1,args=('sxt1',),callback=func2) pool.apply_async(func = func1,args=('sxt2',),callback=func2) pool.apply_async(func = func1,args=('sxt3',),callback=func2) pool.apply_async(func = func1,args=('sxt4',)) pool.apply_async(func = func1,args=('sxt5',)) pool.apply_async(func = func1,args=('sxt6',)) pool.apply_async(func = func1,args=('sxt7',)) pool.apply_async(func = func1,args=('sxt8',)) pool.close() pool.join() '' ' 当前进程的ID:525344,sxt1 当前进程的ID:524032,sxt2 当前进程的ID:523960,sxt3 当前进程的ID:493052,sxt4 当前进程的ID:523844,sxt5 当前进程的ID:525344,sxt6 # sxt6和sxt1的进程号是一致的 sxt1 当前进程的ID:524032,sxt7 sxt2 sxt3 当前进程的ID:523960,sxt8 ' ''
使用with管理线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from multiprocessing import Pool import os from time import sleep def func1(name): print(f"当前进程的ID:{os.getpid()},{name}") sleep(2) return name if __name__ == "__main__": with Pool(5) as pool: args = pool.map(func1,('sxt1,','sxt2,','sxt3,','sxt4,','sxt5,','sxt6,','sxt7,','sxt8,')) for a in args: print(a)
协程
协程,全称是“协同程序”,用来实现任务协作。是一种在线程中,比线程更加轻量级的存在,由程序员自己写程序来管理。
当出现IO阻塞时,CPU一直等待IO返回,处于空转状态。这时候用协程,可以执行其他任务。当IO返回结果后,再回来处理数据。充分利用了IO等待的时间,提高了效率。
控制流的让出和恢复
每个协程有自己的执行栈,可以保存自己的执行现场
可以由用户程序按需创建协程(比如:遇到io操作)
协程“主动让出(yield)”执行权时候,会保存执行现场(保存中断时的寄存器上下文和栈),然后切换到其他协程
协程恢复执行(resume)时,根据之前保存的执行现场恢复到中断前的状态,继续执行,这样就通过协程实现了轻量的由用户态调度的多任务模型
协程的优点
由于自身带有上下文和栈,无需线程上下文切换的开销,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级;
无需原子操作的锁定及同步的开销;
方便切换控制流,简化编程模型
单线程内就可以实现并发的效果,最大限度地利用cpu,且可扩展性高,成本低(注:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理)
协程的缺点
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU的多个核用上,协程需要和进程配合才能运行在多CPU上。
当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
asyncio异步IO实现协程
正常的函数执行时是不会中断的,所以要写一个能够中断的函数,需要加async
async 用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是sleep(5))消失后,也就是5秒到了再回来执行
await 用来用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序。
asyncio是python3.5之后的协程模块,是python实现并发重要的包,这个包使用事件循环驱动实现并发。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncio import time async def func1(): for i in range(3): print(f'北京:第{i}次打印') await asyncio.sleep(1) return "func1执行完毕" async def func2(): for k in range(3): print(f'上海:第{k}次打印' ) await asyncio.sleep(1) return "func2执行完毕" async def main(): res = await asyncio.gather(func1(), func2()) print(res) if __name__ == '__main__': start_time = time.time() asyncio.run(main()) end_time = time.time() print(f"耗时{end_time-start_time}")
网络编程 基础概念 TCP
TCP(Transmission Control Protocol,传输控制协议)。TCP方式就类似于拨打电话,使用该种方式进行网络通讯时,需要建立专门的虚拟连接,然后进行可靠的数据传输,如果数据发送失败,则客户端会自动重发该数据。
UDP
UDP(User Data Protocol,用户数据报协议)
UDP是一个非连接的协议,传输数据之前源端和终端不建立连接, 当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。 在发送端,UDP传送数据的速度仅仅是受应用程序生成数据的速度、 计算机的能力和传输带宽的限制; 在接收端,UDP把每个消息段放在队列中,应用程序每次从队列中读一个消息段。
UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP
TCP和UDP的区别
这两种传输方式都在实际的网络编程中使用,重要的数据一般使用TCP方式进行数据传输,而大量的非核心数据则可以通过UDP方式进行传递,在一些程序中甚至结合使用这两种方式进行数据传递。
由于TCP需要建立专用的虚拟连接以及确认传输是否正确,所以使用TCP方式的速度稍微慢一些,而且传输时产生的数据量要比UDP稍微大一些。
TCP是面向连接的,传输数据安全,稳定,效率相对较低。
UDP是面向无连接的,传输数据不安全,效率较高。
UDP
TCP
是否连接
无连接
面向连接
是否可靠
不可靠传输,不使用流量控制和拥塞控制
是否可靠
连接对象个数
支持一对一,一对多,多对一和多对多交互通信
连接对象个数
传输方式
面向报文
传输方式
首部开销
首部开销小,仅8字节
首部开销
适用场景
适用于实时应用(IP电话、视频会议、直播等)
适用场景
TCP建立连接与断开连接 三次握手
第一步:客户端发送一个包含SYN即同步(Synchronize)标志的TCP报文,SYN同步报文会指明客户端使用的端口以及TCP连接的初始序号。
第二步:服务器在收到客户端的SYN报文后,将返回一个SYN+ACK的报文,表示客户端的请求被接受,同时TCP序号被加一,ACK即确认(Acknowledgement)
第三步:客户端也返回一个确认报文ACK给服务器端,同样TCP序列号被加一,到此一个TCP连接完成。然后才开始通信的第二步:数据处理。
四次挥手
第一步: 当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求 ;
第二步: 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1;
第三步: 由B 端再提出反方向的关闭请求,将FIN置1 ;
第四步: 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束.。
数据包结构
套接子编程概述 socket编程 TCP协议和UDP协议是传输层的两种协议。Socket是传输层供给应用层的编程接口,分为TCP编程和UDP编程两类。
Socket编程封装了常见的TCP、UDP操作,可以实现非常方便的网络编程。
socket()函数 通过使用socket模块提供的socket对象,可以在计算机网络中建立可以互相通信的服务器与客户端。在服务器端需要建立一个socket对象,并等待客户端的连接。客户端使用socket对象与服务器端进行连接
1 2 3 4 5 6 7 8 9 10 11 12 13 Python 中,通常用一个Socket表示“打开了一个网络连接” socket.socket([family[, type [, protocol]]]) family: 套接字家族可以使AF_UNIX或者AF_INET; AF 表示ADDRESS FAMILY 地址族 AF_INET(又称 PF_INET)是 IPv4 网络协议的套接字类型; AF_UNIX 则是 Unix 系统本地通信 type : 套接字类型如果是TCP 用SOCK_STREAM 如果是UDP 用SOCK_DGRAM protocol: 一般不填,默认为0
一些常用socket函数列举
函数
功能
服务器端套接字函数
s.bind()
绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。
s.listen()
开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。
s.accept()
被动接受TCP客户端连接,(阻塞式)等待连接的到来
客户端套接字
s.connect()
主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。
s.connect_ex()
connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv()
接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。
s.send()
发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。
s.sendall()
完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
s.recvfrom()
接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。
s.sendto()
发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。
s.close()
关闭套接字
s.getpeername()
返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。
s.getsockname()
返回套接字自己的地址。通常是一个元组(ipaddr,port)
s.setsockopt(level,optname,value)
设置给定套接字选项的值。
s.getsockopt(level,optname[.buflen])
返回套接字选项的值。
s.settimeout(timeout)
设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect())
s.gettimeout()
返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。
s.fileno()
返回套接字的文件描述符。
s.setblocking(flag)
如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。
s.makefile()
创建一个与该套接字相关连的文件
UDP编程 简单例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 服务端 from socket import *s = socket(AF_INET,SOCK_DGRAM) s.bind(("127.0.0.1" ,8000 )) print ("等待接收中" )recv_data = s.recvfrom(1024 ) print (f"收到{recv_data[0 ].decode('gbk' )} ,来自{recv_data[1 ]} " ) s.close() 客户端 from socket import *s = socket(AF_INET, SOCK_DGRAM) address = ("127.0.0.1" ,8000 ) data = input ("要发送的数据:" ) s.sendto(data.encode("gbk" ),address) s.close() 运行结果如图
UDP持续通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from socket import *s = socket(AF_INET, SOCK_DGRAM) s.bind(("127.0.0.1" ,8000 )) print ("Waiting for connection..." )while True : recv_data = s.recvfrom(1024 ) print (f"收到信息:{recv_data[0 ].decode('gbk' )} ,从{recv_data[1 ]} " ) if recv_data[0 ].decode('gbk' ) == 'EOF' : print ("结束" ) break from socket import *s = socket(AF_INET, SOCK_DGRAM) addr = ("127.0.0.1" ,8000 ) while True : data = input (f"向{addr[0 ]} 发送信息:" ) s.sendto(data.encode("gbk" ),addr) if data == "EOF" : print ("结束" ) break
UDP多线程双工通信 在这种情况下服务端和客户端的区分就不是很明确了,只要调换发送口和接收口即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from socket import *from threading import Threaddef recv_data (): while True : recv_data = s.recvfrom(1024 ) print (f"收到信息:{recv_data[0 ].decode('gbk' )} ,from{recv_data[1 ]} " ) def send_data (): while True : data = input ("发送信息:" ) address = ("127.0.0.1" ,8002 ) s.sendto(data.encode('gbk' ),address) if __name__ == '__main__' : s = socket(AF_INET, SOCK_DGRAM) s.bind(("127.0.0.1" ,8000 )) t1 = Thread(target=recv_data) t2 = Thread(target=send_data) t1.start() t2.start() t1.join() t2.join() from socket import *from threading import Threaddef recv_data (): while True : recv_data = s.recvfrom(1024 ) print (f"收到信息:{recv_data[0 ].decode('gbk' )} ,from{recv_data[1 ]} " ) def send_data (): while True : data = input ("发送信息:" ) address = ("127.0.0.1" ,8000 ) s.sendto(data.encode('gbk' ),address) if __name__ == '__main__' : s = socket(AF_INET, SOCK_DGRAM) s.bind(("127.0.0.1" ,8002 )) t1 = Thread(target=recv_data) t2 = Thread(target=send_data) t1.start() t2.start() t1.join() t2.join()
TCP编程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 在UDP中,因为没有连接,所以在每次发送都需要添加对端的ip和port 创建Socket服务器程序的步骤: (1 )创建Socket对象 (2 )绑定端口号 (3 )监听端口号 (4 )等待客户端Socket的连接 (5 )读取客户端数据 (6 )向客户端发送数据 (7 )关闭客户端socket (8 )关闭服务端socket from socket import *server_socket = socket(AF_INET, SOCK_STREAM) server_socket.bind(("127.0.0.1" ,8999 )) server_socket.listen(5 ) print ("等待连接" )client_socket,client_info = server_socket.accept() recv_data = client_socket.recv(1024 ) print (f"收到信息{recv_data.decode('gbk' )} ,来源{client_info} " )client_socket.close() server_socket.close() from socket import *client_socket = socket(AF_INET, SOCK_STREAM) client_socket.connect("127.0.0.1" ,8999 ) client_socket.send("wangsheng" .encode("utf-8" )) client_socket.close() 运行之后
TCP双向通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from socket import * server_socket = socket(AF_INET, SOCK_STREAM) server_socket.bind(("127.0.0.1",8999)) server_socket.listen(5) print("等待连接") client_socket,client_info = server_socket.accept() print("客户端连接成功") while True: recv_data = client_socket.recv(1024).decode("gbk") print(f"收到消息{recv_data},来源{client_info}") if recv_data == "EOF": print("结束") break msg = input("发送消息:") client_socket.send(msg.encode("gbk")) client_socket.close() server_socket.close() from socket import * client_socket = socket(AF_INET, SOCK_STREAM) client_socket.connect(("127.0.0.1",8999)) print("成功连接") while True: msg = input("发送消息:") client_socket.send(msg.encode("gbk")) if msg == "EOF": break recv_data = client_socket.recv(1024).decode("gbk") print(f"服务器端消息:{recv_data}") client_socket.close() 这种情况只能一问一答,
TCP多线程双工通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 from socket import * from threading import Thread def recv_data(): while True: re_data = tcp_client_socket.recv(1024).decode("gbk") print(f"B:{re_data}") if re_data == 'EOF': break def send_data(): while True: msg = input(">") tcp_client_socket.send(msg.encode("gbk")) if msg == "EOF": break if __name__ == '__main__': tcp_server_socket = socket(AF_INET, SOCK_STREAM) tcp_server_socket.bind(("127.0.0.1",9000)) tcp_server_socket.listen(5) print("等待连接") tcp_client_socket,host = tcp_server_socket.accept() print("连接成功") t1 = Thread(target=recv_data) t2 = Thread(target=send_data) t1.start() t2.start() t1.join() t2.join() tcp_client_socket.close() tcp_server_socket.close() from socket import * from threading import Thread def recv_data(): while True: recv_data = tcp_client_socket.recv(1024).decode("gbk") print(f"A:{recv_data}") if recv_data == 'EOF': break def send_data(): while True: msg = input(">") tcp_client_socket.send(msg.encode("gbk")) if msg == 'EOF': break if __name__ == '__main__': tcp_client_socket = socket(AF_INET, SOCK_STREAM) tcp_client_socket.connect(("127.0.0.1",9000)) print("连接成功") t1 = Thread(target=recv_data) t2 = Thread(target=send_data) t1.start() t2.start() t1.join() t2.join() tcp_client_socket.close() 两边都往对方发送EOF时,双线程都会结束
函数式编程 函数式编程的一些关键概念
偏函数 作用就是把一个函数某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新的函数会更简单。
1 2 3 4 5 6 7 8 9 10 比如int 转8 进制数字,需要使用 int ("123" ,base=8 )全都要转8 进制就要全都带base参数 现在有functools.partial偏函数就可以直接固定base值 import functoolsint2 = functools.partial(int , base=2 ) print (int2('1000000' )) print (int2('1000000' , base=10 ))
闭包
局部变量:如果名称绑定再一个代码块中,则为该代码块的局部变量,除非声明为nonlocal或global
全局变量:如果模块绑定在模块层级,则为全局变量
自由变量 :如果变量在一个代码块中被使用但不是在其中定义,则为自由变量
闭包是一个函数,而且存在于另一个函数当中,可以访问另一个函数的作用域
闭包可以访问到父级函数的变量,且该变量不会销毁
闭包的内存分析
在inner中调用了outer的a变量,返回inner时,a对象不会随着outer关闭而消失,而是由inner继续指向
优点:
1.隐藏变量,避免全局污染
2.可以读取函数内部的变量
使用不当的缺点:
1.导致变量不会被垃圾回收机制回收,造成内存消耗
2.可能会造成内存泄漏的问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 使用闭包在不侵入代码的前提下添加功能 def outfunc (func ): def infunc (*args,**kwargs ): print ("日志纪录 start..." ) func(*args,**kwargs) print ("日志纪录 end..." ) return infunc def fun1 (): print ("使用功能1" ) def fun2 (a,b,c ): print ("使用功能2" ,a,b,c) print (id (fun1))fun1 = outfunc(fun1) print (id (fun1))fun1() fun2 = outfunc(fun2) fun2(100 ,200 ,300 ) 1853641106240 1853641546208 日志纪录 start... 使用功能1 日志纪录 end... 日志纪录 start... 使用功能2 100 200 300 日志纪录 end...
map函数 是一个内置函数,接收两种参数,函数与序列。map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回
如果要将函数作用在序列上,就可以这么操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def f (x ): return x * x L = [] for n in [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ]: L.append(f(n)) print (L)def f2 (x,y ): return x+y L=map (f2,[1 ,2 ,3 ,4 ],[10 ,20 ,30 ]) print (list (L))
reduce函数 属于funtools模块
reduce把一个函数作用在一个序列[x1, x2, x3…]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
1 2 3 4 5 6 from functools import reducedef add (x, y ): return x + y sum =reduce(add, [1 , 3 , 5 , 7 , 9 ])print (sum )
filter函数 内置函数,用于过滤序列,把传入的函数依次作用于每个元素,然后根据返回值是True还是False, 决定保留还是丢弃该元素。
1 2 3 4 5 6 7 8 def is_odd (n ): return n % 2 == 1 L=filter (is_odd, [1 , 2 , 4 , 5 ]) print (list (L))删掉偶数,只留奇数
装饰器 装饰器来自 Decorator 的直译。什么叫装饰,就是装点、提供一些额外的功能。在 python 中的装饰器则是提供了一些额外的功能。
装饰器本质上是一个Python函数(其实就是闭包),它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
装饰器用于有以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 不适用装饰器: def outfunc (func ): def infunc (): func() print ("日志纪录" ) return infunc def fun1 (): print ("使用功能1" ) def fun2 (): print ("使用功能2" ) log1 = outfunc(fun1) log2 = outfunc(fun2) fun1() fun2() 使用装饰器: def log_module (func ): def inner (): func() print ("日志" ) return inner @log_module def log1 (): print ("使用功能1" ) @log_module def log2 (): print ("使用功能2" ) fun1() fun2()
多个装饰器执行顺序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 @mylog @cost_time def fun1 (): pass 等同于 fun2 = cost_time(fun1) fun2 = mylog(fun1) 等同于 fun2 = mylog(cost_time(fun2)) 先执行cost_time函数,再执行mylog函数 import timedef mylog (func ): def inner (): print ("开始记录日志" ) func() print ("结束记录日志" ) return inner def cost_time (func ): print ("cost_time start" ) def inner (): print ("开始计时" ) start = time.time() func() end = time.time() print (f"花费时间{end-start} " ) return end-start print ("cost_time end" ) return inner @mylog @cost_time def fun1 (): print ("开始测试" ) time.sleep(2 ) print ("结束测试" ) fun1() ''' 计时结束 开始记录日志 开始计时 开始测试 结束测试 花费时间2.001138925552368 结束记录日志 '''
带参数的装饰器 在两层封装的装饰器中,因为固定有一层需要写被返回的函数。必须多封装一层,用以传递额外的参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def mylog (type def decorator (func ): def infunc (*args,**kwargs ): if type =="文件" : print ("文件中:日志纪录" ) else : print ("控制台:日志纪录" ) return func(*args,**kwargs) return infunc return decorator @mylog("文件" def fun2 (a,b ): print ("使用功能2" ,a,b) if __name__ == '__main__' : fun2(100 ,200 )
wraps装饰器 一个函数不止有他的执行语句,还有着 name__(函数名),__doc (说明文档)等属性,我们之前的例子会导致这些属性改变。
functool.wraps可以将原函数对象的指定属性赋值给包装函数对象,默认有module、name、doc,或者通过参数选择。
1 2 3 4 5 6 7 8 9 10 11 在使用装饰器的过程中,最外层的函数(在主函数中调用的函数)并不是实际上执行的函数 在内存中都是指向了装饰器中的函数。 可以使用wraps装饰器: def mylog (func ): @wraps(func ) def infunc (*args,**kwargs ): print ("日志纪录..." ) print ("函数文档:" ,func.__doc__) return func(*args,**kwargs) return infunc
内置装饰器 property、staticmethod、classmethodproperty装饰器
用于像访问属性一样来获取一个函数的返回值
1 2 3 4 5 6 7 8 9 10 11 12 class User : def __init__ (self,name,month_salary ): self.name = name self.month_salary = month_salary @property def year_salary (self ): return int (self.month_salary)*12 if __name__ == '__main__' : u1 = User("ws" ,"1800" ) print (u1.year_salary)
staticmethod装饰器
用于类中的静态方法,不经实例化也可以直接调用
1 2 3 4 5 6 class Person : @staticmethod def say_hello (): print ("hello world!" ) if __name__ == '__main__' : Person.say_hello()
classmethod装饰器
用于类方法,传入cls。不经过实例化也可以直接使用类来调用。和staticmethod的区别就是
需要传入参数,所以也需要在最开始的类初始化方法中定义参数
1 2 3 4 5 6 7 8 9 10 class Person : def __init__ (self,name ): self.name = name @classmethod def say_hello (cls,name ): print (f"我是{name} " ) print ("hello world!" ) if __name__ == '__main__' : Person.say_hello("王盛" )
类装饰器 类能实现装饰器的功能, 是由于当我们调用一个对象时,实际上调用的是它的 call 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Demo : def __call__ (self ): print ('我是 Demo' ) demo = Demo() demo() 类装饰器的使用 fun1 函数是作为参数传递给了 NewClass 类的构造函数 __init__ 方法 而不是 __call__ 方法。但当之后调用 fun1() 时,调用NewClass 实例的 __call__ 方法 class NewClass (): def __init__ (self,func ): self.func = func def __call__ (self,*args,**kwargs ): print ("记录" ) return self.func(*args,**kwargs) @NewClass def fun1 (): print (f"使用fun1" ) if __name__ == '__main__' : fun1()
案例:缓存装饰器、计时装饰器 思路:通过time设计计时器,通过定义cache字典来做缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 对于同个输入没有必要重新执行,直接使用缓存输出结果即可 from time import sleep,timedef cost_time (func ): def inner (*args, **kwargs ): start = time() result = func(*args,**kwargs) end = time() print (f"耗时为{end-start} " ) return result return inner class Cache (): __cache={} def __init__ (self,func ): self.func = func def __call__ (self,*args,**kwargs ): if self.func.__name__ in Cache.__cache: return Cache.__cache[self.func.__name__] else : result = self.func(*args, **kwargs) Cache.__cache[self.func.__name__] = result return result @cost_time @Cache def long_time (): print ("启动 1" ) sleep(3 ) print ("结束 2" ) return "函数结束" if __name__ == '__main__' : r1 = long_time() r2 = long_time() print (r1) print (r2) 启动 1 结束 2 耗时为3.000478744506836 耗时为0.0 函数结束 函数结束
生成器 在Python中,一边循环一边计算的机制,称为生成器:generator
比如如果仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都浪费了。如果列表元素按照某种算法推算出来,那我们就可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。
是一种以时间换空间的方式
1 2 3 4 5 6 7 8 生成器表达式很简单,只要把一个列表推导式的[]改成(),就创建了一个生成器(generator) L = [x * x for x in range (10 )] print (L)g = (x * x for x in range (10 )) print (g)
生成器函数 如果一个函数中包含yield关键字,那么这个函数就不再是一个普通函数,调用函数就是创建了一个生成器(generator)对象。
生成器仅仅保存了一套生成数值的算法,并且没有让这个算法现在就开始执行,根据调用来进行计算与返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 def test (): print ("start" ) i = 0 while i <3 : yield i print (i) i += 1 print ("end" ) return "结束" if __name__ == '__main__' : a = test() print (a) a.__next__() a.__next__() a.__next__() a.__next__() ''' 相当于每次调用它的__next__,都会执行这个yield yield执行完之后会让程序挂起 return代表生成器结束,就会返回报错 ''' send()函数,将值100 发到生成器内部 def foo (): print ("start" ) i = 0 while i<4 : temp = yield i print (f"temp:{temp} " ) i=i+1 print ("end" ) g = foo() print (next (g)) print ("******" )print (g.send(100 ))print (next (g)) start 0 ****** temp:100 1 temp:None 2
迭代器 特点
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()
实现了iter方法和next方法的对象就是迭代器。
生成器都是Iterator对象,但list、dict、str虽然是Iterable(可迭代对象),却不是Iterator(迭代器)。
1 2 3 4 5 6 7 8 9 10 from collections.abc import Iteratorfrom collections.abc import Iterablea = isinstance ([],Iterable) print (a) a = isinstance ([],Iterator) print (a)True False []是可迭代对象,但不是迭代器
Python的Iterator对象表示的是一个数据流 。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
所以,生成器一定是迭代器。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
for循环的本质 是使用next()来实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 for x in [1 , 2 , 3 , 4 , 5 ]: pass 本质上是 it = iter ([1 , 2 , 3 , 4 , 5 ]) while True : try : x = next (it) except StopIteration: break
如果要自己创建一个迭代器,就需要分别重写__tier__方法和__next__方法
动态语言特性 动态语言指的是运行时可以改变其结构的语言 :例如新的函数、 对象、甚至代码可以被引进, 已有的函数可以被删除或是其他结构上的变化。
给对象添加属性和方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import typesclass Person (): def __init__ (self,name,age ): self.name = name self.age = age p1 = Person("wangsheng" ,24 ) p2 = Person("xuehuiying" ,24 ) p1.height = 176 print (p1.height) def fun1 (self ): print (f"{self.name} is {self.age} " ) p2.fun1 = types.MethodType(fun1,p2) p2.fun1()
给类添加属性和方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 **添加静态方法与类方法: import typesclass Persion (): pass def static1 (): print ("static~" ) Persion.static = staticmethod (static1) Persion.static() @classmethod def cls1 (cls,name ): cls.name = name print (f'cls~{cls.name} ' ) Persion.clsfunc = cls1 Persion.clsfunc("ws" )
__slots__ 属性**
__slots__对动态添加成员变量、成员方法有限制。对动态添加类属性、类方法没有限制。__slots__只对本类有限制,不限制子类
为的是不让别人乱加
变量的类型标注 变量类型注解是用来对变量和函数的参数返回值类型做注解(暗示),帮助开发者写出更加严谨的代码,让调用方减少类型方面的错误,也可以提高代码的可读性和易用性。
常用的数据类型
Type
Description
int
整型 integer
float
浮点数字
bool
布尔(int 的子类)
str
字符 (unicode)
bytes
8 位字符
object
任意对象(公共基类)
List[str]
字符组成的列表
Tuple[int, int]
两个int对象的元组
Tuple[int, …]
任意数量的 int 对象的元组
Dict[str, int]
键是 str 值是 int 的字典
Iterable[int]
包含 int 的可迭代对象
Sequence[bool]
布尔值序列(只读)
Mapping[str, int]
从 str 键到 int 值的映射(只读)
Any
具有任意类型的动态类型值
Union
联合类型
Optional
参数可以为空或已经声明的类型
Mapping
映射,是 collections.abc.Mapping 的泛型
MutableMapping
Mapping 对象的子类,可变
Generator
生成器类型, Generator[YieldType、SendType、ReturnType]
NoReturn
函数没有返回结果
Set
集合 set 的泛型, 推荐用于注解返回类型
AbstractSet
collections.abc.Set 的泛型,推荐用于注解参数
Sequence
collections.abc.Sequence 的泛型,list、tuple 等的泛化类型
TypeVar
自定义兼容特定类型的变量
Generic
自定义泛型类型
NewType
声明一些具有特殊含义的类型
Callable
可调用类型, Callable[[参数类型], 返回类型]
NoReturn
没法返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 对于简单的 Python 内置类型,只需使用类型的名称 a:int = 10 b:str = "ws" c:float = "1.12" d:bool = True mypy是Python的可选静态类型检查器,pip安装这个模块之后,在终端中指定mypy就可以对指定 文件进行检查 如果需要标注一些序列的类型,在3.10 之前需要引入对应的模块 from typing import List , Set , Dict , Tuple x:List [int ] = [1 ] x:Set [int ] = {6 , 7 } x:Dict [str , float ] = {'field' : 2.0 } x:Tuple [int ,str ,float ] = (3 , "yes" , 7.5 ) x:Tuple [int , ...] = (1 , 2 , 3 )
函数参数返回值添加类型标注 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def stringify (num:int ) -> str : return str (num) print (stringify(10 ))def plus (num1: int , num2: int ) -> int : return num1 + num2 print (plus(10 ,20 ))from typing import Iteratordef g (n: int ) -> Iterator[int ]: i = 0 while i < n: yield i i += 1
混合类型标注 1 2 3 4 5 6 7 8 9 from typing import Union def oldFunc (para:Union [int ,float ] )->Union [int ,float ]:def newFunc (para:int |float )-> int |float : return para+10 print (newFunc(10 ))print (newFunc(10.10 ))
给类型添加别名 这样可以直接用别名代替类型名,增加代码的可读性
通过typing的TypeAlias方法进行修改别名
1 2 3 4 5 from typing import TypeAliasnewname: TypeAlias = str def newFunc (param:newname ) -> newname: return param + param user = create_user("john_doe" )
散装新特性 字典的三个方法新增mapping属性
1 2 3 4 5 6 7 8 9 mydict = {"一" :1 ,"二" :2 ,"三" :3 } keys = mydict.keys() values = mydict.values() items = mydict.items() print (keys.mapping,values.mapping,items.mapping)
函数zip()新增strict参数
strict表示严格检查要zip的两个对象元素数量是否一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 keys = ['one' ,'two' ,'three' ,'four' ] values = [1 ,2 ,3 ,4 ,5 ] print (dict (zip (keys,values)))print (dict (zip (keys,values,strict=True )))报错:
dataclass装饰器
这个装饰器是Python 3.7及以后版本中引入的,可以很容易地定义一个数据类,而无需手动编写那些常见的特殊方法。这不仅可以减少代码量,还可以提高代码的可读性和可维护性。
dataclass装饰器将根据类属性生成数据类和数据类需要的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 from dataclasses import dataclassfrom typing import ClassVar@dataclass class Player : name:str number:int postion:str age:int =field(default=19 ,repr =False ) country:ClassVar[str ] p1 = Player('SXT' ,18 ,'PG' ,26 ) print (p1)
dataclasses.dataclass(*, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
key
含义
init
指定是否自动生成__init__,如果已经有定义同名方法则忽略这个值,也就是指定为True也不会自动生成
repr
同init,指定是否自动生成__repr__;自动生成的打印格式为class_name(arrt1:value1, attr2:value2, …)
eq
同init,指定是否生成__eq__;自动生成的方法将按属性在类内定义时的顺序逐个比较,全部的值相同才会返回True
order
自动生成__lt__,__le__,__gt__,__ge__,比较方式与eq相同;如果order指定为True而eq指定为False,将引发ValueError;如果已经定义同名函数,将引发TypeError
unsafehash
如果是False,将根据eq和frozen参数来生成__hash__:1. eq和frozen都为True,__hash__将会生成2. eq为True而frozen为False,__hash__被设为None3. eq为False,frozen为True,__hash__将使用超类(object)的同名属性(通常就是基于对象id的hash) 当设置为True时将会根据类属性自动生成__hash__,然而这是不安全的,因为这些属性是默认可变的,这会导致hash的不一致,所以除非能保证对象属性不可随意改变,否则应该谨慎地设置该参数为True
frozen
设为True时对field赋值将会引发错误,对象将是不可变的,如果已经定义了__setattr__和__delattr__将会引发TypeError
1 2 3 例如: @dataclass(init=False , repr =False , eq=False )
字典合并
python3.9之后的新特性
1 2 3 4 5 6 7 8 9 10 11 12 13 dict1.update(dict2) print (dict1)dict1 = {'a' : 1 , 'b' : 2 } dict2 = {'b' : 3 , 'c' : 4 } dict3 = dict1 | dict2 dict1 |= dict2 等价于 dict1 = dict1 | dict2
match新用法
3.10后的新特性,用来取代if_else的语法,效率更高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 语句的匹配 status = 400 match status: case 200 : print ('访问成功' ) case 404 : print ('资源不存在' ) case 502 : print ('网关有问题' ) case 500 : print ('服务有问题' ) case _: print ('不能识别' ) 模式的匹配 person1 = ('ws' ,25 ,'male' ) person2 = ('xhy' ,24 ,'female' ) person3 = ('zhz' ,25 ,'male' ) def func (person ): match person: case (name,_,'female' ): print (f'{name} is woman' ) case (name,_,'male' ): print (f'{name} is man' ) case (name,age,gender): print (f'{name} is {age} old' ) func(person1) func(person2) func(person3)
内存管理机制(八股文) Python是由C语言开发的,底层操作都是基于C语言实现,Python中创建每个对象,内部都会与C语言结构体维护一些值。
1.在创建对象时,每个对象至少内部4个值,PyObject结构体 (上一个对象、下一个对象、类型、引用个数)。
1 2 3 4 5 6 7 8 struct _object *_ob_next; \ struct _object *_ob_prev; typedef struct _object { _PyObject_HEAD_EXTRA Py_ssize_t ob_refcnt; PyTypeObject *ob_type; } PyObject;
2.有多个元素组成的对象使用PyVarObject,里面由:PyObject结构体(上一个对象、下一个对象、类型、引用个数)+Ob_size(items=元素,元素个数)。
1 2 3 4 typedef struct { PyObject ob_base; Py_ssize_t ob_size; /* Number of items in variable part */ } PyVarObject;
在python程序中创建的任何对象都会被放在refchain双向列表链表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 例: f = 3.14 ''' 内部会创建: 1.开辟内存 2.初始化 ob_fval = 3.14 值 ob_type = float 类型 ob_refcnt = 1 引用数量 3.将对象加入到双向链表refchain中 _ob_next = refchain中的上一个对象-上一个指针 _ob_prev = refchain中的下一个对象-下一个指针 '''
Python的缓存机制 小整数对象池 一些整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间。
Python 对小整数的定义是 [-5, 257) 这些整数对象是提前建立好的,不会被垃圾回收。
1 2 3 4 5 6 7 8 9 a = -5 b = -5 a is b -6 -> False 256 -> True 257 -> False 每个大整数,均创建一个新的对象
intern机制 每个单词(字符串),不夹杂空格或者其他符号,默认开启intern机制,共享内存,靠引用计数决定是否销毁
1 2 3 4 5 6 7 a = 'helloworld' b = 'helloworld' a和b是同一个对象,如果使用下划线也是同个对象 a = 'hello world' b = 'hello world' 不是同一个对象
free_list机制 当一个对象的引用计数器为0时,按理说应该回收,但内存不会直接回收,而是将对象添加到free_list链表中缓存。以后再去创建对象时,不再重新开辟内存,而是直接使用free_list。
比如float,list,tuple,dict都有free_list机制
1 2 3 4 5 6 f = 3.14 print (id (f))ff = 3.14 del f print (id (ff))
float类型,维护的free_list链表最多可缓存100个float对象。
list类型,维护的free_list数组最多可缓存80个list对象。
tuple类型,维护一个free_list数组且数组含量20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 重复创建相同元素数量的元组,放入free_list中后,会占用相同的位置 a = (1 ,2 ,3 ) print (id (a))del ab = (4 ,5 ,6 ) print (id (b))a = {'a' :1 ,"b" :2 } print (id (a))del ab = {'c' :3 ,"d" :4 } print (id (b))1779322404736 1779322404736
↑dict类型,维护的free_list数组最多可缓存80个dict对象。运行方式与元组是一致的
垃圾回收机制 Python 内部采用 引用计数法 ,为每个对象维护引用次数,并据此回收不再需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时有内存泄露风险,因此 python 还采用 标记清除法 来回收存在循环引用的垃圾对象。此外,为了提高垃圾回收( GC )效率,Python 还引入了 分代回收机制 。
引用计数法 引用计数 是计算机编程语言中的一种 内存管理技术 ,它将资源被引用的次数保存起来,当引用次数变为 0 时就将资源释放。
Python 也使用引用计数这种方式来管理内存,每个 Python 对象都包含一个公共头部,头部中的 ob_refcnt 字段便用于维护对象被引用次数。回忆对象模型部分内容,我们知道一个典型的 Python 对象结构如下:
引用计数增加的情况
对象被创建
如果有新的对象使用该对象
作为容器对象的一个元素
被作为参数传递给函数
引用计数减少的情况
对象的引用被显示的销毁
新对象不再使用该对象
对象从列表中被移除,或者列表对象本身被销毁
函数调用结束
引用计数机制的优点
引用计数机制的缺点
维护引用计数消耗资源
循环引用的问题无法解决——如下所示
1 2 3 4 5 6 7 8 a = [1 ,2 ] b = [3 ,4 ] a.append(b) b.append(a) del adel b相互引用的这种情况下,计数器a和b都无法归零
标记清除法 引用计数法能够解决大多数垃圾回收的问题,但是遇到两个对象相互引用的情况,del语句可以减少引用次数,但是引用计数不会归0,对象也就不会被销毁,从而造成了内存泄漏问题。针对该情况,Python引入了标记-清除机制 。
主动思路一般分为两步:垃圾识别 和 垃圾回收 。垃圾对象被识别出来后,回收就只是自然而然的工作了,因此垃圾识别是解决问题的关键。
遍历活跃对象,第一步需要找出 根对象 ( root object )集合。所谓根对象,就是指被全局引用或者在栈中引用的对象,这部对象是不能被删除的。
根对象本身是 可达的 ( reachable ),不能删除;被根对象引用的对象也是可达的,同样不能删除;以此类推。我们从一个根对象出发,沿着引用关系遍历,遍历到的所有对象都是可达的,不能删除。
而没有被标色的对象就是 不可达 ( unreachable )的垃圾对象,可以被安全回收。循环引用的致命缺陷完美解决了!
也就是它的关键是“遍历来标记不可达的对象”,并且将其删除
分代回收机制 如果每次执行标记清除法时,都需要遍历所有对象,多半会影响程序性能。
对象存活时间越长,它们被释放的概率越低,可以适当降低回收频率;相反,对象存活时间越短,它们被释放的概率越高,可以适当提高回收频率。
Python 内部根据对象存活时间,将对象分为 3 代
随着时间的推进,程序冗余对象逐渐增多,达到一定阈值,系统进行回收。
这 3 个代分别称为:初生代 、中生代 以及 老生代 。当这 3 个代初始化完毕后,对应的 gc_generation 数组大概是这样的:
第一代链表:
当第一代达到700,就开始检测哪些对象引用计数变成0了,把不是0的放到第二代链表里,此时第一代链表就是空了,当再次达到700时,就再检测一遍。
第二代链表:
当第二代链表达到10,就检测一次。
第三代链表:
第三代链表检测10之后,第三代链表检测一次。
1 2 3 4 5 6 7 8 9 10 11 import gcprint (gc.get_threshold()) gc.get_count() gc.set_threshold() gc.disable()